Question
API Adobe PDF Extract text JSON missed result
Sorry to repost here, I can't delete the other post in the general discussion forum.
I am using Adobe PDF Extractor API. The <require('@adobe/pdfservices-node-sdk')> thing. It converts PDF to a readable JSON file.
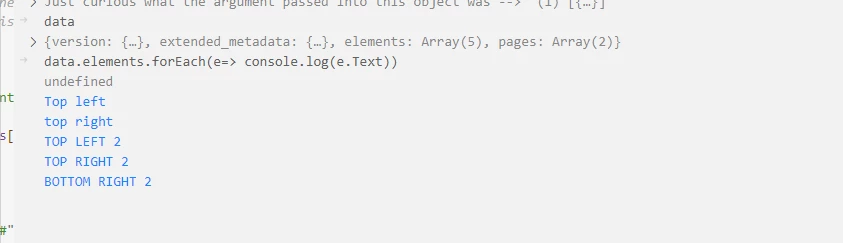
I have a simple PDF file that has basic words on the corners, 4 per corner, 2 pages. Total results should be 8, but I am getting only 5 elements when examining the output JSON file.
How is this API missing such a simple test case?
If it can't extract information accurately from a basic example, how much confidence can I have for much larger more complex PDF's?
Should have: top left, top right, bottom left, bottom right, top left 2, top right 2, bottom left 2, bottom right 2.