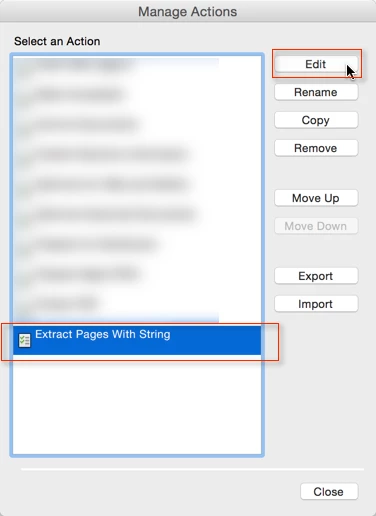
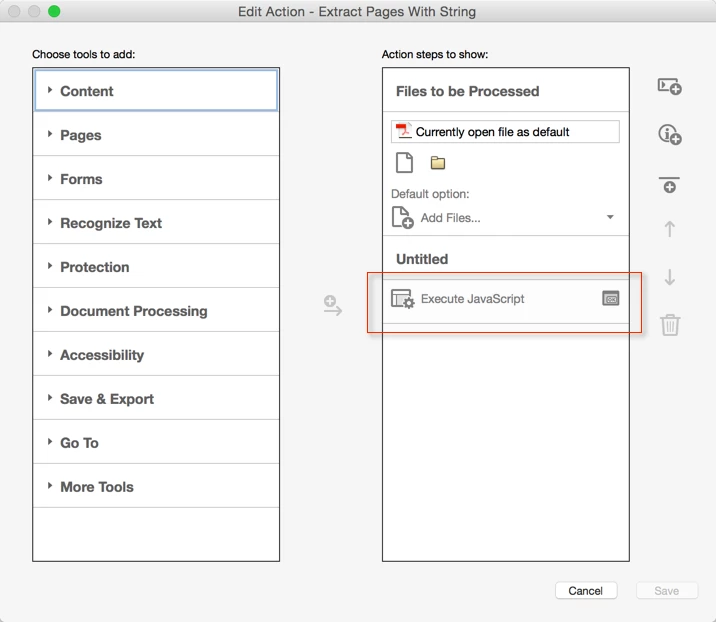
Extract PDF Pages Based on Content
Every fall and winter I have to work with PDF files that are hundreds of pages. Last fall I came across a java script that I was able to run and it worked beautifully. In the last year, I have either lost more brain cells or acrobat dc doesn't work the same way as acrobat X. I need to find a way to extract the pages based off of a word search and save those pages to another file. I would appreciate any suggestions. Also, I have added the java script that was used last year. Thanks in advance for your help.
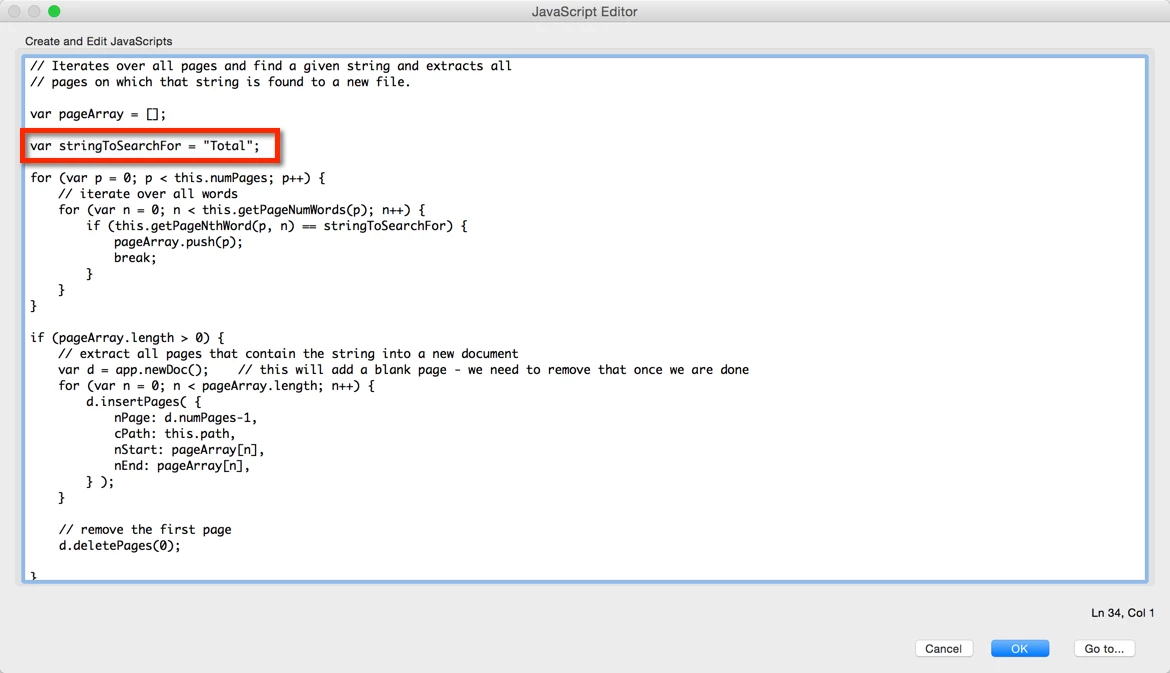
// Iterates over all pages and find a given string and extracts all
// pages on which that string is found to a new file.
var pageArray = [];
var stringToSearchFor = "Total";
for (var p = 0; p < this.numPages; p++) {
// iterate over all words
for (var n = 0; n < this.getPageNumWords(p); n++) {
if (this.getPageNthWord(p, n) == stringToSearchFor) {
pageArray.push(p);
break;
}
}
}
if (pageArray.length > 0) {
// extract all pages that contain the string into a new document
var d = app.newDoc(); // this will add a blank page - we need to remove that once we are done
for (var n = 0; n < pageArray.length; n++) {
d.insertPages( {
nPage: d.numPages-1,
cPath: this.path,
nStart: pageArray
nEnd: pageArray
} );
}
// remove the first page
d.deletePages(0);
}