Question
How to extract an image from PDF document and save on disk
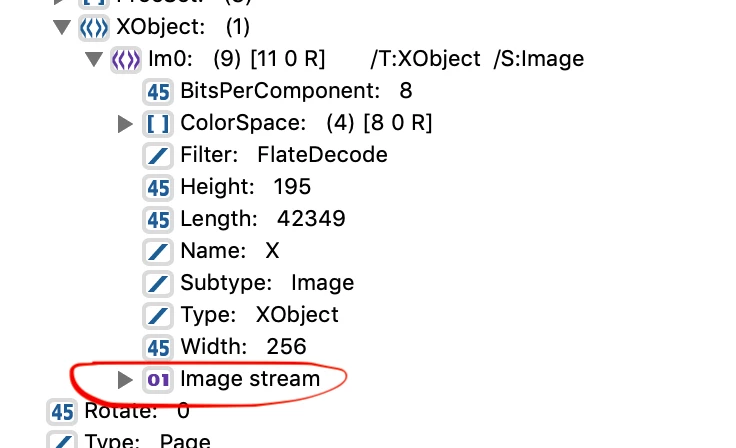
I am exploring SDK samples, where I have found a sample code to extract image info using PDDocEnumResources API which is calling callback procedure with Cos obj, as per sample code it is easy to extract image info of XObject as mentioned in this screenshot but how to extract this Image Stream from CosObj ?