

- Home
- InDesign
- Discussions
- Re: Importing CSV file with Data Merge Fails
- Re: Importing CSV file with Data Merge Fails
Importing CSV file with Data Merge Fails

Copy link to clipboard
Copied
Specs
See pasted text from CSV at http://pastebin.com/mymhugpN
I am using InDesign CS6 (8.0.1)
I created the CSV by downloading it from a Google Spreadsheet as a CSV. I confirm with the Terminal that the character encoding is utf-8 usnig the file command.
Problem detailed
I am trying to import a CSV file (utf-8) with Data Merge via the Select Data Source... command with Show Import Options checked. When viewing the Data Source Import Options dialog, I set the following options—Delimiter:Comma, Encoding:Unicode, Platform:Macintosh. I leave Preserve Spaces in Data Source unchecked. It fails to import any variables and produces no error message. I have tried other CSV files as well (created TextEdit, Espresso, etc.) and it seems that InDesign will not import any files if Unicode is specified as the encoding, no matter which other options are specified.
Can anyone else confirm this?
Importing as ACSII works, but obviously does not display my content correctly.


 52
Replies
52
52
Replies
52
Copy link to clipboard
Copied
Thanks Peter--especially if you can read this when I hit post...
Mike
Copy link to clipboard
Copied
I still don't know what the problem was with posting yesterday. Admin says the error we were seeing usually means the spam filter kicked in because of something in the text, but all I did last night was remove a line of asterisks and it posted just fine, and as far as I know a line of asterisk is not flagged by the filters.

Copy link to clipboard
Copied
Have been following this thread with some interest as a user who uses Data Merge all of the time. Very rarely do I come across this issue, but when I do it is normally when the job is in a hurry.
I've downloaded the csv from the google file and noted the same thing the OP had noticed, and that was the quotes appearing as the OP had stated in part 18 of this thread.
My solution was to go into Textwrangler on a Mac and save the file as the following:

Then, went back into InDesign, selected "Select Data Source", and (making sure that "Show Import Options" is checked ON) selected the new database. A dialog box should now appear with these options:

and voila! The data should go from bad to good!

Copy link to clipboard
Copied
You are still not there, Flash.
Compare the right-hand side of your last screen shot to the one below:

See the difference? Look at the raw source again. There are double quotes, a lower and higher ascii quote. The lower ascii quote gets stripped. Download the ZIP at the link in my last message Peter was kind enough to post when I couldn't.
Take care, Mike
Copy link to clipboard
Copied
Actually. I think the stripping of the outer quote is correct for a .csv file. It's there to inidcate everything inside should be treated as literal, including commas, so that you don't wind up with extra fields.
Copy link to clipboard
Copied
Not to rain on any parades, but IMHO Pete has it right. The opening and closing quotes of that field aren't meant to be there. I stand by my screenshot.
My situation may also not be the same as the OPs, but I've had issues in the past from what FileMaker Pro calls tab delimted files (.tab) and that is twofold:
- When importing into InDesign, I get the same dialog box as Peter did in the third post of this thread; and
- If I do manage to place the file after saving a bad way, I then get the problem that the OP had in the 18th post of this thread.
Thanks to this thread I have now overcome the latter issue....
...However I do not know if saving as specified in my earlier post will resolve the former issue as I don't have FileMaker Pro. Has anyone experienced this before?
Colly
Copy link to clipboard
Copied
Colly—what you mentioned in post #27 fixed my problem, too. Thank you.
However, I still don't understand—what's the problem with the Google Docs-generated utf-8 file? Why does InDesign display the characters that way?
Copy link to clipboard
Copied
Not for a tab delimited file. I know of no other application that mix and match delimiters. one should be able to have triple setz of quotes with a tab delimited file.
plus under certain circumstances, only the leading double quote is stripped.
i will stand by my assertion that id is goofing up a tab delimted utf-8 merge when double quotes are are present.
Copy link to clipboard
Copied
Mike,
The file was saved as .csv, not tab delimited...
Copy link to clipboard
Copied
I think there is a bit of mixed communications here so I just want to clear this up.
The problem I am having is SIMILAR, but not IDENTICAL to the OP's issue.
The OP's data from post #20 only had straight quotation marks in the second to last field of each record, presumably because the other fields did not contain commas but the second to last field did; and is to ensure that only items within the straight quotation marks are the data for that field, and not where any commas may be.
I have seen this happen before but can't reliably say what software does/doesn't do this.
To confirm my theory, look at any reccord after the Devotion reference (e.g. Psalm 147:3 for example) and there is a comma to separate the field, then a straight quote. The end of that field does not always have a "double quote" but instead has a straight quote followed by a comma. I think the "double quote" is a red herring.
My dramas were spelled out in post #30 of this thread, and am on the lookout for any test data that can be supplied from FileMaker Pro, preferably exported as a .tab file; and featuring soft-returns in any of the sample data so I can replicate the fault from my old client.
Copy link to clipboard
Copied
Peter, mine are tab delimited. I.e., I stripped/converted the OP's database and thought I had made it clear above in the post you posted for me. The reason is with all the quotes, double quotes and commas in the narrative text, it is the only means of maintaining them else ID (properly) gets confused as to what to strip and what to retain.
For 15 years, I owned a company that wrote vertical market database publishing software. Mainly for the upper end of the insurance company spectrum (AIG, Zurich, and various entities operating under the Loyds of London umbrealla--which isn't an actual insurance company but that is another story--etc.).
We usually had to use tab delimited merges due to the same issue. I didn't need to jump through the hoops as seen in this thread to produce the merge. Plain ascii files for Word were used in the offices, but mostly used large-scale databases, sometimes using ZIM to interface, sometimes direct for the underrating, quotes and actuary reporting. I know it can be done without stripping the quote marks is the point.
Take care, Mike
Copy link to clipboard
Copied
But because YOU chose to convert from .csv to tab delimited doesn't mean the quote marks belong in merged data. You chose to preserve marks that inthe normal course of working with .csv are stripped out, so you can't say that preserving the .csv format during any of the translations and having those marks stipped in the final merge is an error.
I tend to use tab-delimited text for files like this, myself, but had they been saved that way origianlly I'm quite confident that the outer quotes would not have been included. Reading the text I see no indication that the entire block is a quotation with nested quotes inside (and most style guides would have nested quotes into single quote marks rather than double).
I bet if you resave your tab-delimited file that preserved the outer quotes as .csv from your text editor and open it again you'll find an additional set of new quotes outside.
Copy link to clipboard
Copied
It looks like I may not have the behavior for tab-delimited text entirely correct, as far as the adding of quotation marks, but here's a couple of screen shots to illustrate what happens when you save as .csv from Excel. I've never used Google Spreadsheet, but I don't have any reason to think it would behave differentely, or if it did that ID would understand that the file coming from Google as .csv was somehow different from one coming from another application and it should preserve quotes that would otherwise be discarded.
The text in Excel:
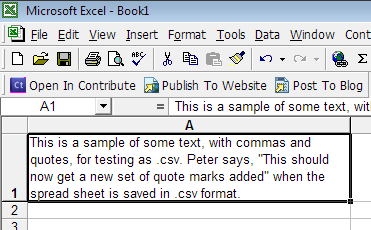
Note that there are no surrounding quotation marks.
The .csv opened in Notepad:

Now there are extra quotes surrounding the internal quote and the entire text string. I was surprised to see that Excel added the same quotes in the tab-delimited file I also saved, so it looks identical.
And this is that same .csv file merged into ID (after adding a header row in Notepad):

Extra quotes are stripped out as they should be.
Copy link to clipboard
Copied
Microsoft explains that if extra quote marks are not desired, one needs to use a macro to prevent Excel from adding them. I have VBA code that does this.
Without input from the OP, we may never know if the quote marks in the various fields are desired or not. In the raw paste, they are there, so I was going by that. I agree that style-wise, I would use italics for proper titles such as the beginning of record 8. I wouldn't quote the artist's description., etc.
Another (possible) means of obviating the ascii vs. unicode, utf-8 vs. utf-16 BE issue(s) might be to convert to XML. This has an added advantage of not needing to stitch the data merge's frames, copy/paste into another story, etc.

It's been a fun exercise and debate. I have not used ID's XML importing (mapping to styles, etc.) before, nor done much data merges with it. My stuff is rather pedestrian.
Take care, Mike

Copy link to clipboard
Copied
Someone have solution to this? have two quotes in .csv file


Copy link to clipboard
Copied
This worked for me. Thanks a lot!

Copy link to clipboard
Copied
I've run into similar problems. I'm using OpenOffice to create a spreadsheet that I export to CSV, and use that as the data source for an InDesign CS2 document. When exporting from OO, if I use the default UTF-8 setting, and open the CSV file in TextWrangler, it shows as "UTF-8 with no BOM". If I resave it as UTF-8, it fails to import.
The thing is, I have some symbols in the Apple Symbols font that I need to import into my document. When the spreadsheet is exported as UTF-8, the file imports, but the symbols don't print correctly, but they show up correctly in Textwrangler. I found, through trial and error, that if I create the CSV file using the plain "Unicode" setting, then open it up in Textwrangler, it shows up as "Unicode UTF-16". I then import this data source into InDesign CS2, using the options "Unicode" and "PC", and it works perfectly.
I'm on Mac OS X 10.5.8 Intel.

Copy link to clipboard
Copied
Yesterday I had the same problem on my Mac. Because of polish letters like: ą, ę, ś, ź, ż I needed to find a solution. I tried to import csv file into InDesign CC and importing as Unicode UTF-8 didn't work. Finally i tried OpenOffice with exporting csv file with classic Unicode with no extension and it works great with InDesign.
In my opinion this problem should be fixed by Adobe because it is more than a year when it exist. Or at least it should be described in Help.


Copy link to clipboard
Copied
Try to use a tab stop separated txt file instead of a coma separated CSV file. When I work on the Mac in German I have the same problems with CSV, with TAB it works fine. I use always unicode UTF 16 as this supports Eastern European Characters like polish additional to or Western Languages like English or French.
Copy link to clipboard
Copied
Thank you Willi Adelberger but as you can see I already fixed this problem with using Open Office and export to Unicode without UTF-8 or UTF-16.

Copy link to clipboard
Copied
Thankyou to the above answers to use a unicode UTF-16 csv file instead of UTF-8.
I had the similar problem of quotation marks appearing incorrectly when imported InDesign via Data Merge,  .
.
I made the csv in Numbers on a Mac which defaults to UTF-8.
When I changed this to Unicode UTF-16 and used the InDesign import options 'Comma, Unicode, PC' the quotation marks appeared correctly in the merged pdf file made by InDesign  .
.

Copy link to clipboard
Copied
This is also how I do it
1. Export CSV from Google Sheets.
2. Open the csv file in Numbers . (check for any empty columns in design will report these as nulls)
3. Export to CSV...
4. Open the Advanced disclosure triangle
5. Choose UTF-16
Import into InDesign... and merge file. MY ISSUE was the use of Arabic characters in the document that did not show correctly with UTF-8, but also that Indesign Failed to open the file.

Copy link to clipboard
Copied
It needs to be saved as UTF-16 with the BOM preserved.
For Mac, export as CSV and then open it in TextEdit, Sublime Text or a similar editor that can save in different encodings. In TextEdit you need to hold option while clicking File and then selecting Save As ... and then selecting Unicode (UTF-16) as the encoding
In Windows use Notepad or a similar editor.

Copy link to clipboard
Copied
When using data merge always ensure your targeted data base file is closed!!
Data merge will not work if the targeted file is open in the original program

Copy link to clipboard
Copied
Hi,
The easiest way that i have discover just, if you are merging data from excel to csv and your file supports unicode-8 or unicode-16 characcters dont try to save file in csv first save as file in unicode-16.txt format than rename it and change files extension in csv.
when you rename this file and open in texteditor or notepad it change the character, when you merge data in ID it shows correct data.

Find more inspiration, events, and resources on the new Adobe Community
Explore Now
 AdChoices
AdChoices