Mark has pretty much nailed this already, but i will point out that i usually achieve the same effects by using regular expressions syntax to specify Unicode ranges. For example, "every glyph past basic ASCII" would be
[/x{0100}-/x{FFFF}]+
You can make a GREP style that applies to e.g. only Thai Unicode ranges. It can get complicated, as in the case of parentheses in CJK text that are not fullwidth, but it works quite well to capture All the Glyphs in a given writing system.
That's the sort of thing I was looking for Joel! Thanks. Also, I notice that Indesign grep can understand \p{Punctuation} which is great, but not other unicode blocks, eg. \p{Han}.
@iampurple you can implement the grep with Joel's method by changing the grep to something like:
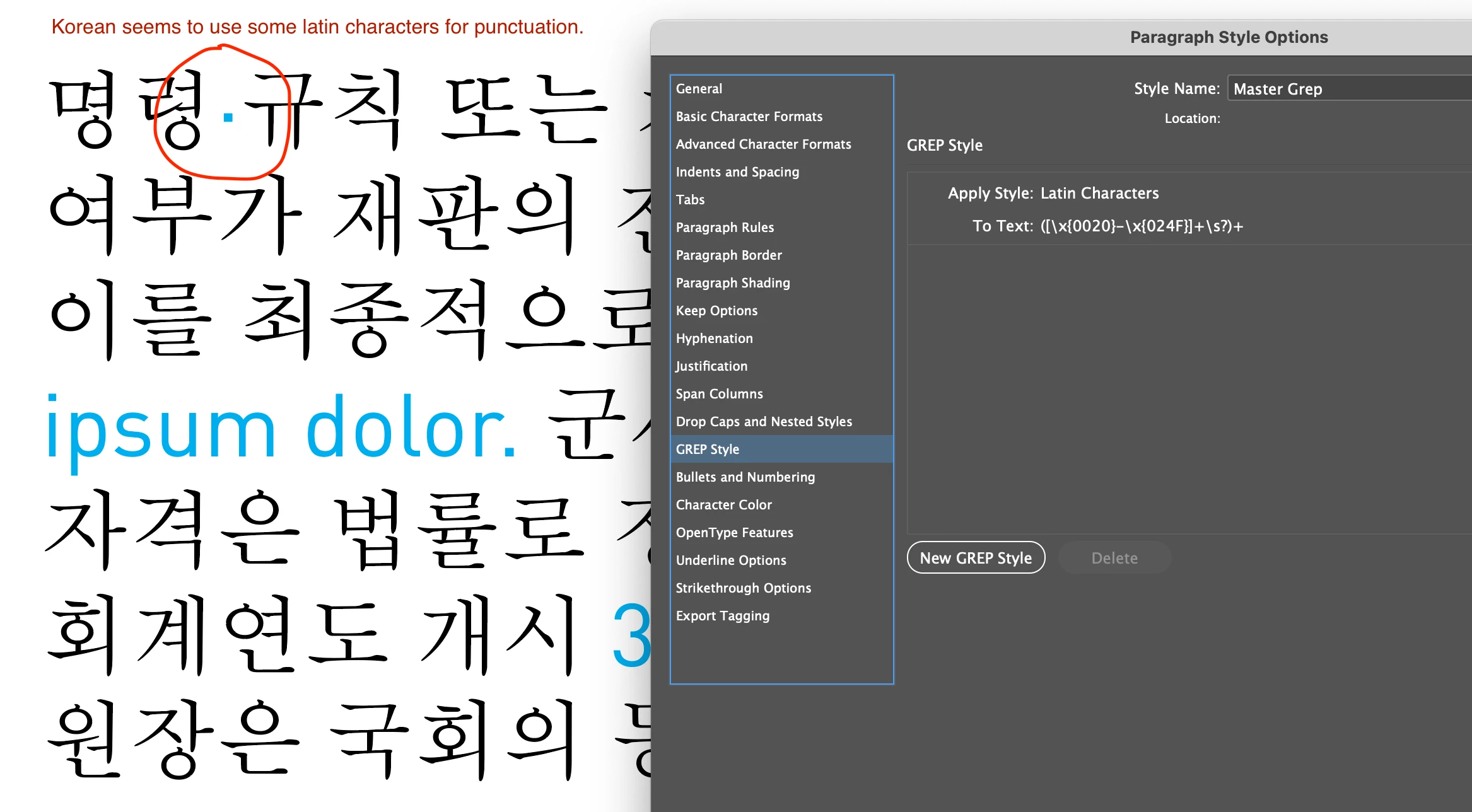
([\x{0020}-\x{024F}]+\s?)+
(By the way, see unicode blocks here.)
You may still have to go more sophisticated with the grep though, if you don't want to match some things, for example Korean seems to use some latin punctuation characters: