
Multiple record data merge into paragraph styles-applies the wrong style
Hi, I've been working on this project for sometime and everytime I manage to get one part of the workflow to work another seems to break. My agency publishes catalogs in multiple formats: large-print, audio, braille, and HTML. I've been trying to redesing our work process so that the catalogs will be laid out from merged data out of comma-separated file. The data merges have worked fairly well in Word, but InDesign is a challenge. I'm merging multiple records on a page, like a mailing label. The paragraphs need to be formatted and I'm trying to apply a paragraph style to them. After much work, I think I've finally got the data merge to work correctly, but the wrong paragraph styles are applied. I'm going to apply a new master page to the data once the data is merge that uses the paragraph styles for text variable running headers and I need to build a table of contents based on the paragraph styles so I need this to work. Attached are some screenshots.
Master page set up for data merge with paragraph styles:
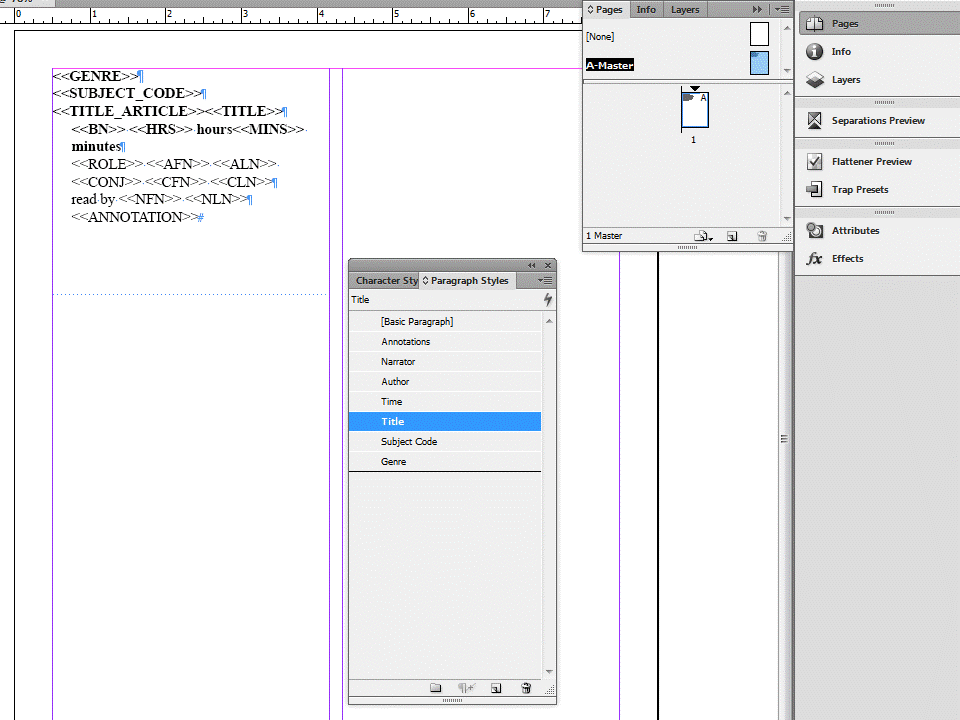
Here is the merged document with the wrong paragraph styles applied:
I have only a few weeks to get this process ironed out to keep to our rigorous production schedule. If anyone can help I would really appreciate it.
thanks,
Lina