Answered
No Break names
Multiple times I have to work with texts that have names and roman numbers after the name like Paul VI or Louis XVI. There is a way to have a list of names and apply the "no break" definition to that list?

Multiple times I have to work with texts that have names and roman numbers after the name like Paul VI or Louis XVI. There is a way to have a list of names and apply the "no break" definition to that list?
Arrrg, i made an mistake. As you see in "about Ludwig"...there is "no break" and thats wrong. So I have modified the GREP:
[\l\u]\s[\u]{2,}
Now it reads like this.
Try to find a character, low- or upcase, with a blank behind, with 2 or more characters following, which must be upcased.
But if you have like ChicoPereira12 I (the first), that will break, because im assuming your roman numbers always have minimum 2 charcaters.
I would restrict the possibilities even more. After all, you know that this should only be applied to "end of proper name + space + roman capital number". This GREP will only match such a final lowercase plus uppercase roman numbers:
\l\s[IVXLC]+\b
(lowercase, space, one or more of "IVXLC", end-of-word). It does not validate the notation of the roman number! (Then again, if you're suspicious this may run rampant on your text, set a limit to the length of the roman sequence to something reasonable.)
As you can see it does not mark the entire name:
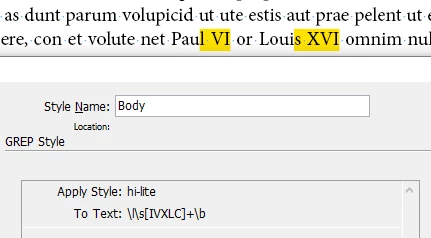
which may or may be what you want. If you don't want to break any proper name, you could prepend this GREP with "\u\l+", but of course then you are fixing the wrong thing: sure, it won't allow names followed by roman numbers to be broken, but of course names without will still break. So instead, just uncheck "Hyphenate Capitalised Words" in your Hyphenation settings.
Already have an account? Login
Enter your E-mail address. We'll send you an e-mail with instructions to reset your password.