
Why does Premiere sometimes break transcripts into short lines and other times group them into full
Hello! I’m using Adobe Premiere Pro’s 2025 (25.2.3 Build 4 on Mac OS) built-in transcription tool (Text Panel → Transcribe Sequence) to generate transcripts from voice-over audio. I’m following the exact same steps for different sequences:
- I select the audio track.
- Click “Transcribe sequence.”
- Let Premiere auto-generate the transcript.
But I’m seeing inconsistent behavior:
In some sequences, the transcript is broken into very short lines—almost like individual sentence captions.
In others, Premiere groups entire thoughts or blocks of narration into longer paragraphs, which is what I want.
Same workflow, same speaker, same language (English), and same version of Premiere. The only difference I’ve noticed might be the speech rhythm or pause timing, but the inconsistency is really frustrating.
Is this related to the “Detect speakers” checkbox during transcription? Or something else—like how Premiere interprets pauses or delivery style?
Has anyone else figured out how to force paragraph-style grouping consistently?
See below an example of the behavior that I don't want, the transcript is broken into very short lines with several errors.
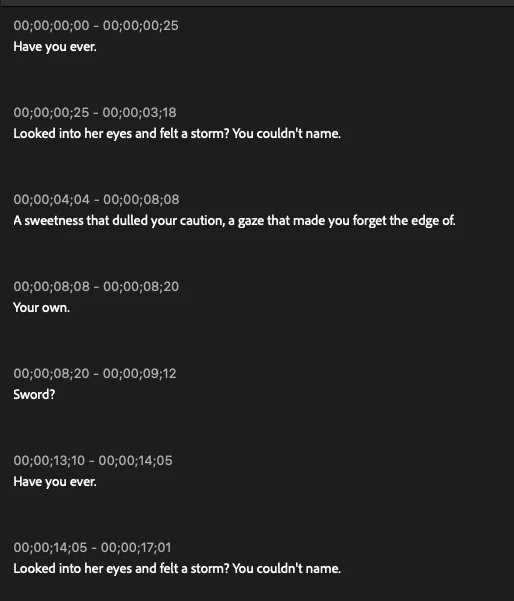
And here is an example of the type of transcript that sometimes I get, and I want, longer paragraphs with almost no errors. Which I do on some instances, but I don't know how!
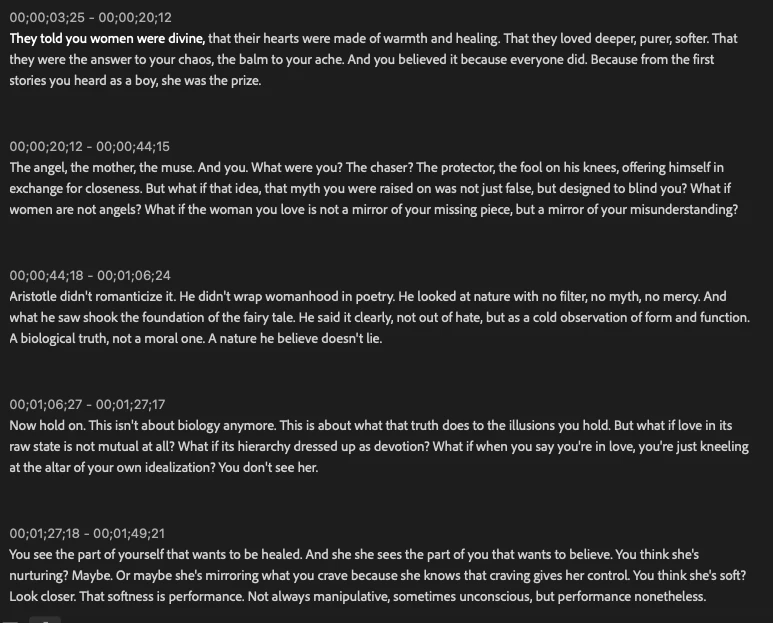
Thanks in advance!