Answered
OCR: Page elements get rotated instead of leaving them level
- July 8, 2024
- 1 reply
- 3421 views
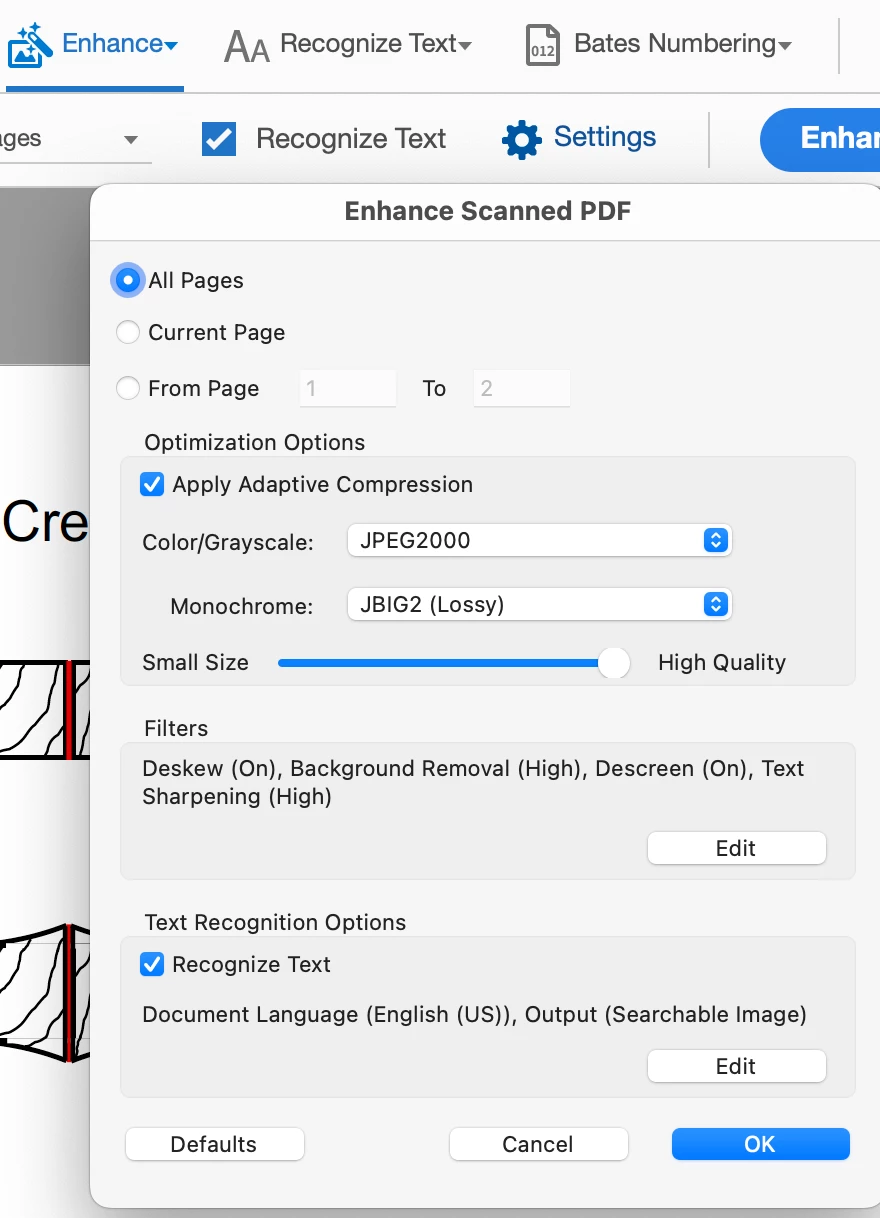
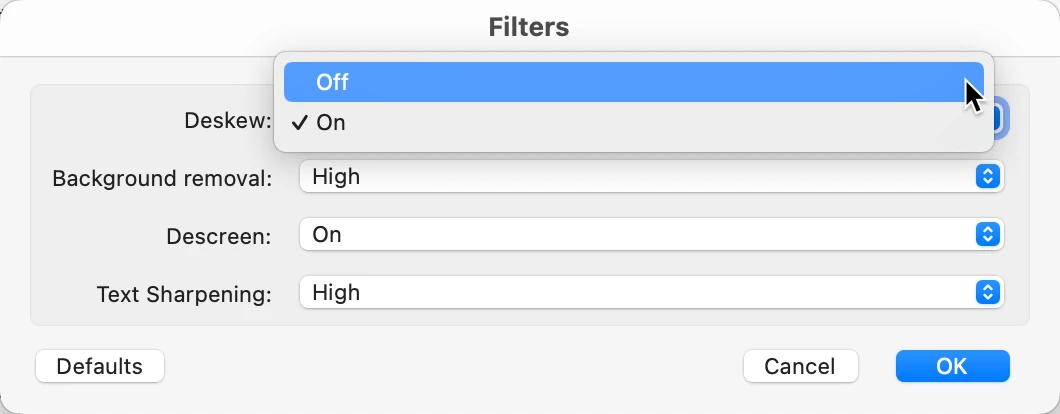
I would like to OCR the attached PDF page, preferably into editable text and images. However, whatever I try, it rotates the elements on the page by something like 20°. If I select Searchable Image (Exact), then the recognized text gets rotated. The rotation doesn’t even make sense.
How do I tell Acrobat not to rotate the elements on the page?