Removing hidden text from document - Acrobat standard tool is not finding it.
- May 5, 2023
- 2 replies
- 3649 views
Hi,
I have an odd issue with some PDFs that I have to extract data from, and I'm hoping for some support to unpick the problem.
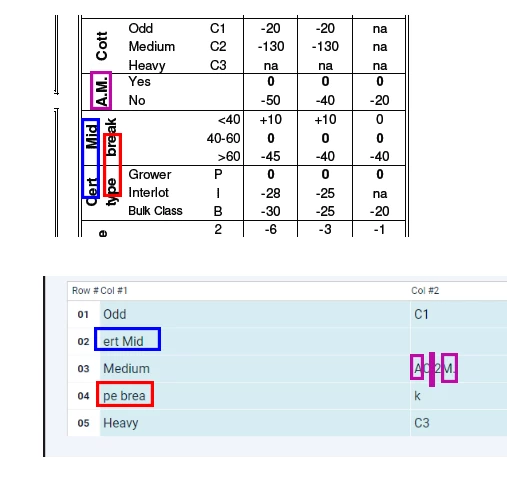
The files appear to have text in them that is hidden in some way other than what might be considered normal. If the attached PDF is viewed in Acrobat, it appears ok but when I run a parser over it to extract the data from partular parts of the doc (using docparser.com, but I'm confident the issue lies in the PDF, not the parser) there is additional text appearing in parts of the doc.
An example problem area is the small table on the right hand side of page 2 titled 'Cott' with rows of 'Odd', 'Medium' and 'Heavy'. I'm extracting that particular area - just the table data, not the vertical title - with the parser, and there is text appearing in it that cannot be seen when viewing the doc in Acrobat.
I've tried the following in Acrobat:
Removing form fields
Running the 'Remove hidden text' operation.
Neither of these operations are finding that extra text and I'm out of ideas. Hoping that somebody can assist with removing anything that can't be seen without flattening the document to an image (resulting in the need to do OCR after, which is not an option in this case).