

Answered
Split PDF by Top level bookmarks does not work
Hi,
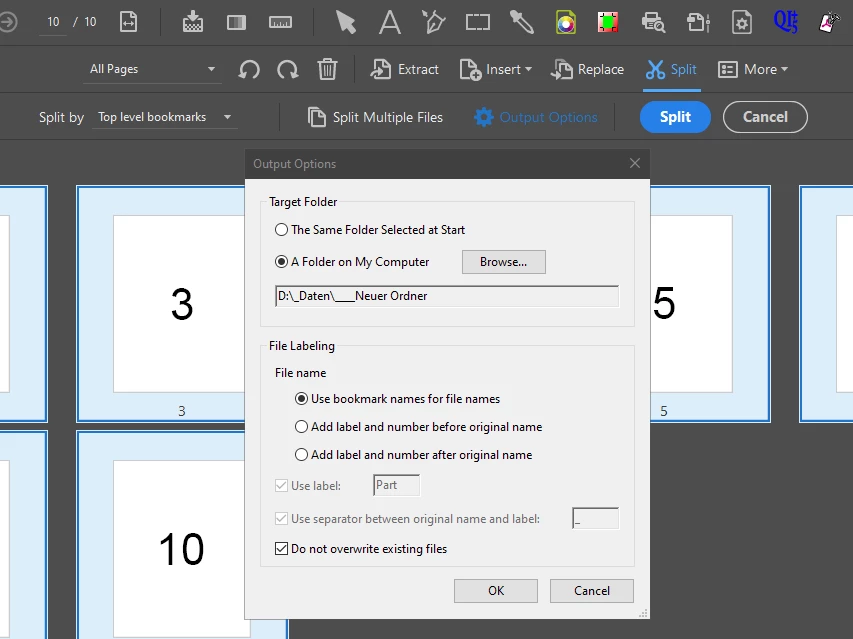
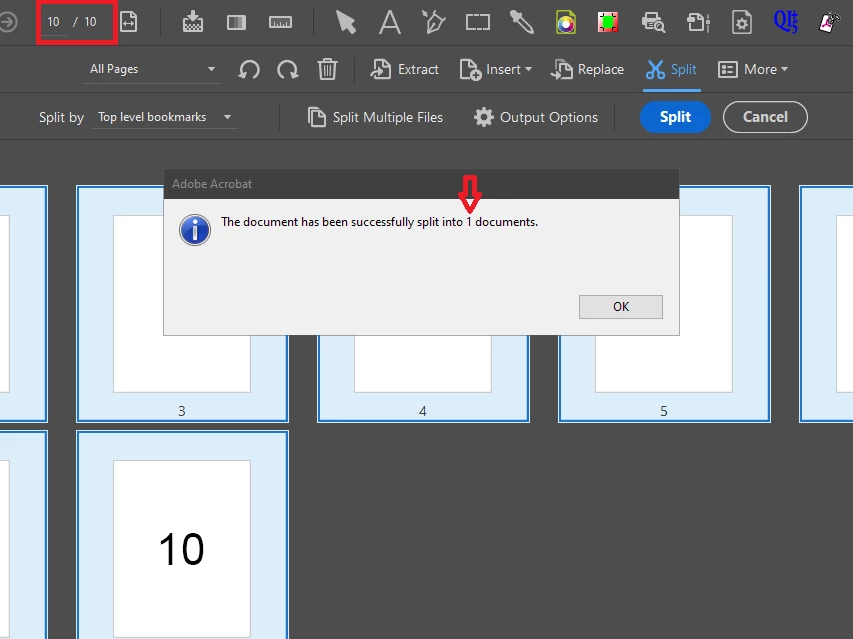
I use Adobe Acrobat's own split function to split a PDF into single-page PDFs whose file names are made up of the bookmarks of the source PDF. Each page can be accessed with its own bookmark. The bookmark 'Page_1' leads to page 1 and should be written out as a separate PDF with the file name 'Page_1.pdf'.
I create the bookmarks in the PDF with the following JavaScript. After splitting, however, only a single PDF is written out. Why isn't a separate PDF written out for each page, as I specify in the settings for splitting?
var root = this.bookmarkRoot;
for (var i = 0; i < this.numPages; i++)
{
root.createChild("Page_" + (i+1), "this.pageNum=" + i, i);
}
yosimo