

Question
Trying to deskew pages, get text overlaid?
Hello!
I'm trying to deskew a scanned document, but it seems that no matter what settings I use, the document ends up having recognized text overlaid on the original image. I've included an example of what I mean here:
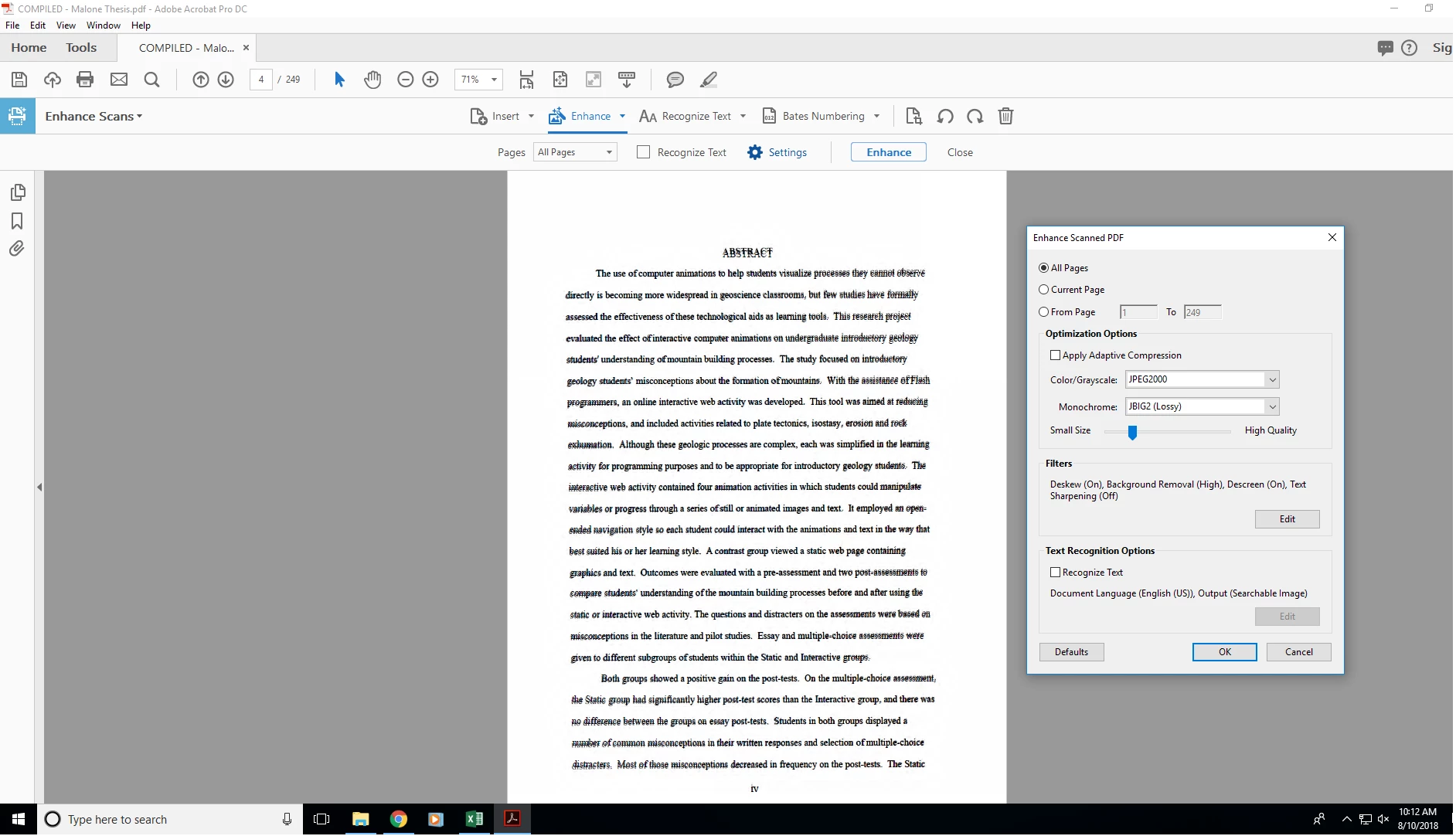
I'm using Adobe Acrobat Pro DC on a Windows 10 system.
Any advice?