

Help With Regexp Lookaheads to Extract Definitions
Am trying to extract definitions from a document glossary with a script. Have run into a problem with my lookahead that I can't seem to sort. Glossary entries look like image below:
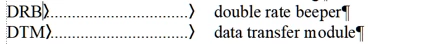
The problem is that each entry may have one or two tabs. The first tab is rendered as "......" separating the acronym from the definition. Some glossaries have a second tab that appears as a blank space before the definition. The following works fine for glossaries with a single tab.
(?<=\bDRB\x08).*However, if glossary uses two tabs, regexp picks up the second tab along with the definition. If I change my look ahead to:
(?<=\bDRB\x08\x08).*It works for with two tabs, but not with one. If I change it to:
(?<=\bDRB\x08+).*...which should find one or more occurance of the tab character, I get a "Not Found" error. Apparently operators do not work that same way in ascertions as they work in regexps.