

- Home
- InDesign
- Discussions
- Re: Activating Browser window from within an InDes...
- Re: Activating Browser window from within an InDes...
Activating Browser window from within an InDesign Javascript
.png)
Copy link to clipboard
Copied
Hi All
A part of a Javascript I have inherited, relies on Applescript to call to open the active Safari/Chrome window, and extract some information, then use this in the JS with InDesign.
What I would like to do is eliminate AS altogether, as this restricts me to using Macs, and would like to open this up to PC users too.
I know I can do a platform query, and may be an option to use VBScript to do the equivalent AS routine. I have absolutely no experience with VBScript, so would need some help if this is the option.
Ideally I would like to stay as native JS, but that may be wishful thinking on my part.
Here is a sample of the AS I am using within a doScript:
tell application "Safari"
activate
set imagePath to do JavaScript "frames[2].frames[1].document.links[0].href" in document 1
end tell
then...
tell application "InDesign"
activate
end tell
Does anyone know if this may be possible?
Cheers
Roy


 39
Replies
39
39
Replies
39

Copy link to clipboard
Copied
*Bump*

Copy link to clipboard
Copied
Searching the forum you can find examples like this (written by Muppet Mark):
// OpenBrowserWithJavascript.jsx
// siehe http://forums.adobe.com/message/4904789#4904789
openURL( 'www.google.com' );
function openURL( address ) {
var f = File( Folder.temp + '/aiOpenURL.url' );
f.open( 'w' );
f.write( '[InternetShortcut]' + '\r' + 'URL=http://' + address + '\r' );
f.close();
f.execute();
};
Have fun


Copy link to clipboard
Copied
@pixxxel schubser – that code by Muppet Mark is working very well.
Thank you for sharing the link.
Leaves the question: Is it possible to determine a specific browser but the one the operating system is chosing?
On my Mac OSX 10.6.8 I'd like to open a particular URL not in Safari, but in Firefox.
Firefox seems to be my default browser, because if I saved a website to my file system and double click the *.html file I will always get Firefox (even if it's *not* already open).
With the script above executed Safari will open.
I did not find a control for that behavior in my OSX 10.6.8.
Uwe
Copy link to clipboard
Copied
Hallo Uwe,
kannst du überprüfen, mit welchem Standardprogramm dein Dateityp *.url verknüpft ist?
Oder noch einfacher: suche einfach nach der vom Skript angelegten "aiOpenURL" Internetverknüpfung und öffne dann die Informationen am Mac bzw. die Eigenschaften unter Windows dieser Datei ( Die im Screenshot beispielhaft gezeigte "aiOpenURL" ist der im OpenBrowser-Skript vergebene Name für die Url)
Hello Uwe,
can you check, which is the standard programm for the file format *.url?
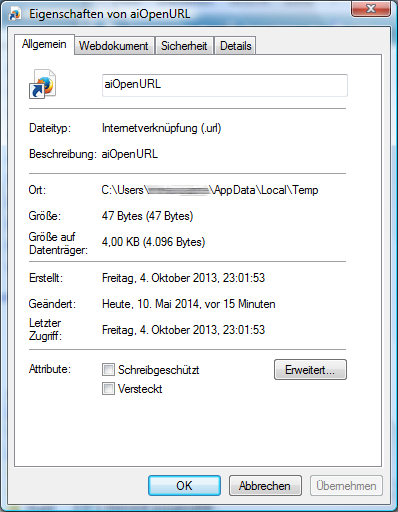
Viele Grüße
pixxxelschubser
Copy link to clipboard
Copied
@pixxxelschubser – thank you for that tip. But it didn't work as expected with Firefox.
I changed it back to Safari. And that was working quite well.
See what happened.
First I set file type url to open with Firefox with a text file renamed with *.url instead of *.txt. Clicked "Change All":
(Change should affect all files with file type url, not only that particular one)
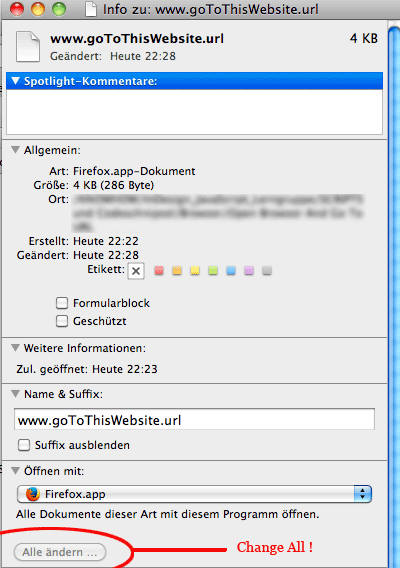
Then I ran the code from ESTK. Firefox started (good!), but was showing the contents of the file (not so good!).
Firfox did not open the url contained by the file:

Uwe
Copy link to clipboard
Copied
Sadly, if you read the original post, you will see that Roy does not need to open a new page, he needs to extract information from a browser window that is already open by the user. This is a specific requirement, in which Muppet Markscript does not correctly solve.
Copy link to clipboard
Copied
Hi pixxxel Schubser
thanks for the reply, but what I am really needing (if possible) is a way to extract information from the current page open in the browser, then return the results back to ID for actions.
do you know of a way to do this without resorting to AS?
thanks again
Royston.
Copy link to clipboard
Copied
Hi,
There is a function created by Rorohiko Man - Kris Coppieters - kris@rorohiko.com
It writes url body contents into .txt file. No browser involved.
Playing with TXT could lead you to "extract information"
Code below uses this function:
var
mFolder = "~/Documents",
url = "http://sport.interia.pl/bundesliga/news-robert-lewandowski-krolem-strzelcow-bundesligi,nId,1423502",
fileName = url.split("/"),
fileName = fileName[fileName.length - 1],
mFile = File(mFolder + "/" + fileName + ".txt");
var urlData = GetURL(url, false);
if (urlData != null && urlData.body != null) {
mFile.open("w");
mFile.write(urlData.body);
mFile.close();
}
function GetURL(url,isBinary)
{
//
// This function consists of up to three 'nested' state machines.
// At the lowest level, there is a state machine that interprets UTF-8 and
// converts it to Unicode - i.e. the bytes that are received are looked at
// one by one, and the Unicode is calculated from the one to four bytes UTF-8
// code characters that compose it.
//
// The next level of state machine interprets line-based data - this is
// needed to interpret the HTTP headers as they are received.
//
// The third level state machine interprets the HTTP reply - based on the
// info gleaned from the headers it will process the HTTP data in the HTTP
// reply
//
//
// If things go wrong, GetURL() will return a null
//
var reply = null;
//
// Below some symbolic constants to name the different states - these
// make the code more readable.
//
const kUTF8CharState_Complete = 0;
const kUTF8CharState_PendingMultiByte = 1;
const kUTF8CharState_Binary = 2;
const kLineState_InProgress = 0;
const kLineState_SeenCR = 1;
const kProtocolState_Status = 1;
const kProtocolState_Headers = 2;
const kProtocolState_Body = 3;
const kProtocolState_Complete = 4;
const kProtocolState_TimeOut = 5;
do
{
//
// Chop the URL into pieces
//
var parsedURL = ParseURL(url);
//
// We only know how to handle HTTP - bail out if it is something else
//
if (parsedURL.protocol != "HTTP")
{
break;
}
//
// Open up a socket, and set the time out to 2 minutes. The timeout
// could be parametrized - I leave that as an exercise.
var socket = new Socket;
socket.timeout = 120;
//
// Open the socket in binary mode. Sockets could also be opened in UTF-8 mode
// That might seem a good idea to interpret UTF-8 data, but it does not work out
// well: the HTTP protocol gives us a body length in bytes. If we let the socket
// interpret UTF-8 then the body length we get from the header, and the number of
// characters we receive won't match - which makes things quite awkward.
// So we need to use BINARY mode, and we must convert the UTF-8 ourselves.
//
if (! socket.open(parsedURL.address + ":" + parsedURL.port,"BINARY"))
{
break;
}
//
// Dynamically build an HTTP 1.1 request.
//
if (isBinary)
{
var request =
"GET /" + parsedURL.path + " HTTP/1.1\n" +
"Host: " + parsedURL.address + "\n" +
"User-Agent: InDesign ExtendScript\n" +
"Accept: */*\n" +
"Connection: keep-alive\n\n";
}
else
{
var request =
"GET /" + parsedURL.path + " HTTP/1.1\n" +
"Host: " + parsedURL.address + "\n" +
"User-Agent: InDesign ExtendScript\n" +
"Accept: text/xml,text/*,*/*\n" +
"Accept-Encoding:\n" +
"Connection: keep-alive\n" +
"Accept-Language: *\n" +
"Accept-Charset: utf-8\n\n";
}
//
// Send the request out
//
socket.write(request);
//
// readState keeps track of our three state machines
//
var readState =
{
buffer: "",
bufPos: 0,
//
// Lowest level state machine: UTF-8 conversion. If we're handling binary data
// the state is set to kUTF8CharState_Binary which is a 'stuck' state - it
// remains in that state all the time. If the data really is UTF-8 the state
// flicks between kUTF8CharState_PendingMultiByte and kUTF8CharState_Complete
//
curCharState: isBinary ? kUTF8CharState_Binary : kUTF8CharState_Complete,
curCharCode: 0,
pendingUTF8Bytes: 0,
//
// Second level state machine: allows us to handle lines and line endings
// This state machine can process CR, LF, or CR+LF line endings properly
// The state flicks between kLineState_InProgress and kLineState_SeenCR
//
lineState: kLineState_InProgress,
curLine: "",
line: "",
isLineReadyToProcess: false,
//
// Third level state machine: handle HTTP reply. This state gradually
// progresses through kProtocolState_Status, kProtocolState_Headers,
// kProtocolState_Body, kProtocolState_Complete.
// contentBytesPending is part of this state - it keeps track of how many
// bytes of the body still need to be fetched.
//
protocolState: kProtocolState_Status,
contentBytesPending: null,
dataAvailable: true,
//
// The HTTP packet data, chopped up in convenient pieces.
//
status: "",
headers: {},
body: ""
};
//
// Main loop: we loop until we hit kProtocolState_Complete as well as an empty data buffer
// (meaning all data has been processed) or until something timed out.
//
while
(
! (readState.protocolState == kProtocolState_Complete && readState.buffer.length <= readState.bufPos)
&&
readState.protocolState != kProtocolState_TimeOut
)
{
//
// If all data in the buffer has been processed, clear the old stuff
// away - this makes things more efficient
//
if (readState.bufPos > 0 && readState.buffer.length == readState.bufPos)
{
readState.buffer = "";
readState.bufPos = 0;
}
//
// If there is no data in the buffer, try to get some from the socket
//
if (readState.buffer == "")
{
//
// If we're handling the body of the HTTP reply, we can try to optimize
// things by reading big blobs of data. Also, we need to look out for
// completion of the transaction.
//
if (readState.protocolState == kProtocolState_Body)
{
//
// readState.contentBytesPending==null means that the headers did not
// contain a length value for the body - in which case we need to process
// data until the socket is closed by the server
//
if (readState.contentBytesPending == null)
{
if (! readState.dataAvailable && ! socket.connected)
{
//
// The server is finished with us - we're done
//
socket = null;
readState.protocolState = kProtocolState_Complete;
}
else
{
//
// Attempt to read a byte
//
readState.buffer += socket.read(1);
readState.dataAvailable = readState.buffer.length > 0;
}
}
else
{
//
// If the socket is suddenly disconnected, the server pulled the
// rug from underneath us. Register this as a time out problem and
// bail out.
//
if (! readState.dataAvailable && ! socket.connected)
{
socket = null;
readState.protocolState = kProtocolState_TimeOut;
}
else
{
//
// Try to get as much data as needed from the socket. We might
// receive less than we've asked for.
//
readState.buffer = socket.read(readState.contentBytesPending);
readState.dataAvailable = readState.buffer.length > 0;
readState.contentBytesPending -= readState.buffer.length;
//
// Check if we've received as much as we were promised in the headers
// If so, we're done with the socket.
//
if (readState.contentBytesPending == 0)
{
readState.protocolState = kProtocolState_Complete;
socket.close();
socket = null;
}
//
// If we're downloading binary data, we can immediately shove the
// whole buffer into the body data - there's no UTF-8 to worry about
//
if (isBinary)
{
readState.body += readState.buffer;
readState.buffer = "";
readState.bufPos = 0;
}
}
}
}
else if (readState.protocolState != kProtocolState_Complete)
{
//
// We're reading headers or status right now - look out
// for server disconnects
//
if (! readState.dataAvailable && ! socket.connected)
{
socket = null;
readState.protocolState = kProtocolState_TimeOut;
}
else
{
readState.buffer += socket.read(1);
readState.dataAvailable = readState.buffer.length > 0;
}
}
}
//
// The previous stretch of code got us as much data as possible into
// the buffer (but that might be nothing, zilch). If there is data,
// we process a single byte here.
//
if (readState.buffer.length > readState.bufPos)
{
//
// Fetch a byte
//
var cCode = readState.buffer.charCodeAt(readState.bufPos++);
switch (readState.curCharState)
{
case kUTF8CharState_Binary:
//
// Don't use the UTF-8 state machine on binary data
//
readState.curCharCode = cCode;
readState.multiByteRemaining = 0;
break;
case kUTF8CharState_Complete:
//
// Interpret the various UTF-8 encodings - 1, 2, 3, or 4
// consecutive bytes encode a single Unicode character. It's all
// bit-fiddling here: depending on the masks used, the bytes contain
// 3, 4, 5, 6 bits of the whole character.
// Check
// http://en.wikipedia.org/wiki/UTF-8
//
if (cCode <= 127)
{
readState.curCharCode = cCode;
readState.multiByteRemaining = 0;
}
else if ((cCode & 0xE0) == 0xC0)
{
readState.curCharCode = cCode & 0x1F;
readState.curCharState = kUTF8CharState_PendingMultiByte;
readState.pendingUTF8Bytes = 1;
}
else if ((cCode & 0xF0) == 0xE0)
{
readState.curCharCode = cCode & 0x0F;
readState.curCharState = kUTF8CharState_PendingMultiByte;
readState.pendingUTF8Bytes = 2;
}
else if ((cCode & 0xF8) == 0xF0)
{
readState.curCharCode = cCode & 0x07;
readState.curCharState = kUTF8CharState_PendingMultiByte;
readState.pendingUTF8Bytes = 3;
}
else
{
// bad UTF-8 char
readState.curCharCode = cCode;
readState.pendingUTF8Bytes = 0;
}
break;
case kUTF8CharState_PendingMultiByte:
if ((cCode & 0xC0) == 0x80)
{
readState.curCharCode = (readState.curCharCode << 6) | (cCode & 0x3F);
readState.pendingUTF8Bytes--;
if (readState.pendingUTF8Bytes == 0)
{
readState.curCharState = kUTF8CharState_Complete;
}
}
else
{
// bad UTF-8 char
readState.curCharCode = cCode;
readState.multiByteRemaining = 0;
readState.curCharState = kUTF8CharState_Complete;
}
break;
}
//
// If we've got a complete byte or Unicode char available, we process it
//
if (readState.curCharState == kUTF8CharState_Complete || readState.curCharState == kUTF8CharState_Binary)
{
cCode = readState.curCharCode;
var c = String.fromCharCode(readState.curCharCode);
if (readState.protocolState == kProtocolState_Body || readState.protocolState == kProtocolState_Complete)
{
//
// Once past the headers, we simply append new bytes to the body of the HTTP reply
//
readState.body += c;
}
else
{
//
// While reading the headers, we look out for CR, LF or CRLF sequences
//
if (readState.lineState == kLineState_SeenCR)
{
//
// We saw a CR in the previous round - so whatever follows,
// the line is now ready to be processed.
//
readState.line = readState.curLine;
readState.isLineReadyToProcess = true;
readState.curLine = "";
readState.lineState = kLineState_InProgress;
//
// The CR might be followed by another one, or
// it might be followed by a LF (which we ignore)
// or any other character (which we process).
//
if (cCode == 13) // CR
{
readState.lineState = kLineState_SeenCR;
}
else if (cCode != 10) // no LF
{
readState.curLine += c;
}
}
else if (readState.lineState == kLineState_InProgress)
{
//
// If we're in the midsts of reading characters and we encounter
// a CR, we switch to the 'SeenCR' state - a LF might or might not
// follow.
// If we hit a straight LF, we can process the line, and get ready
// for the next one
//
if (cCode == 13) // CR
{
readState.lineState = kLineState_SeenCR;
}
else if (cCode == 10) // LF
{
readState.line = readState.curLine;
readState.isLineReadyToProcess = true;
readState.curLine = "";
}
else
{
//
// Any other character is appended to the current line
//
readState.curLine += c;
}
}
if (readState.isLineReadyToProcess)
{
//
// We've got a complete line to process
//
readState.isLineReadyToProcess = false;
if (readState.protocolState == kProtocolState_Status)
{
//
// The very first line is a status line. After that switch to
// 'Headers' state
//
readState.status = readState.line;
readState.protocolState = kProtocolState_Headers;
}
else if (readState.protocolState == kProtocolState_Headers)
{
//
// An empty line signifies the end of the headers - get ready
// for the body.
//
if (readState.line == "")
{
readState.protocolState = kProtocolState_Body;
}
else
{
//
// Tear the header line apart, and interpret it if it is
// useful (currently, the only header we process is 'Content-Length'
// so we know exactly how many bytes of body data will follow.
//
var headerLine = readState.line.split(":");
var headerTag = headerLine[0].replace(/^\s*(.*\S)\s*$/,"$1");
headerLine = headerLine.slice(1).join(":");
headerLine = headerLine.replace(/^\s*(.*\S)\s*$/,"$1");
readState.headers[headerTag] = headerLine;
if (headerTag == "Content-Length")
{
readState.contentBytesPending = parseInt(headerLine);
if (isNaN(readState.contentBytesPending) || readState.contentBytesPending <= 0)
{
readState.contentBytesPending = null;
}
else
{
readState.contentBytesPending -= (readState.buffer.length - readState.bufPos);
}
}
}
}
}
}
}
}
}
//
// If we have not yet cleaned up the socket we do it here
//
if (socket != null)
{
socket.close();
socket = null;
}
reply =
{
status: readState.status,
headers: readState.headers,
body: readState.body
};
}
while (false);
return reply;
}
function ParseURL(url)
{
url=url.replace(/([a-z]*):\/\/([-\._a-z0-9A-Z]*)(:[0-9]*)?\/?(.*)/,"$1/$2/$3/$4");
url=url.split("/");
if (url[2] == "undefined") url[2] = "80";
var parsedURL =
{
protocol: url[0].toUpperCase(),
address: url[1],
port: url[2],
path: ""
};
url = url.slice(3);
parsedURL.path = url.join("/");
if (parsedURL.port.charAt(0) == ':')
{
parsedURL.port = parsedURL.port.slice(1);
}
if (parsedURL.port != "")
{
parsedURL.port = parseInt(parsedURL.port);
}
if (parsedURL.port == "" || parsedURL.port < 0 || parsedURL.port > 65535)
{
parsedURL.port = 80;
}
parsedURL.path = parsedURL.path;
return parsedURL;
}
TXT should be written in MyDocuments folder. File is named using last part of URL.
It need a few seconds to run (15 on my side)
Jarek
Copy link to clipboard
Copied
@Jarek – just tested the posted code by Kris with your suggested url, that should lead to Robert Lewandowski 🙂
The script generated a txt file. Took a little longer to write the file. About 60 seconds.
However the file generated was empty.
0 Bytes.
Checked the URL with my browser. No problem. Cmd+u in Firefox was showing the html code. Ok. Nothing unusual.
<!DOCTYPE html><!--[if lt IE 7]> <html class="no-js ie6 oldie" lang="pl"> <![endif]-->
<!--[if IE 7]> <html class="no-js ie7 oldie" lang="pl"> <![endif]-->
<!--[if IE 8]> <html class="no-js ie8 oldie" lang="pl"> <![endif]-->
<!--[if gt IE 8]><!--> <html class="no-js" lang="pl"> <!--<![endif]-->
<head>
<meta charset="UTF-8">
Then I tried with a differnt url. This time a www address of my favourite pub here in my hometown.
A rather small web site.
That worked.
Here some lines of html revealed by the browser:
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/1999/xhtml" lang="en" xml:lang="en">
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
vs. the code in the text file written:
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/1999/xhtml" lang="en" xml:lang="en">
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
No difference to spot. Also all used special characters used in the html, like umlauts, were written well (not presented here).
But I had to be careful what encoding I have to chose when opening the file by TextEdit.app on OSX 10.6.8.
"Automatic" did not work. Therefore double-clicking the file generated an error message, that something's wrong with the encoding of UTF8.
Then I tried with "Western Europe (Mac OS Roman)".
That finally did the trick. 🙂
So, I have one positive sample and one negative one.
Jarek, I think, you tested that code with that particular url and it worked fine for you.
What to make out of this now?
Uwe

Copy link to clipboard
Copied
Hum, the forum emails you when mentioned… I didn't write that function… Probably/very likely a lift off one of the Ps boys…
That said I don't think what Roy wants can be done in just extendscript…

Copy link to clipboard
Copied
does the above script still work (this is a very old post)
I need to open a particular website in safari from within a javascript i run in indesign.
when i run the above script-Safari launchs but then a page that says "safari cant open page " "operation couldnt be completed" (see attached). i have changed the URL multiple times with same result
Copy link to clipboard
Copied
above i am referring to the short script at the very top by muppet mark and posted by pixxxel...
Copy link to clipboard
Searching the forum you can find examples like this (written by Muppet Mark):
// OpenBrowserWithJavascript.jsx
// siehe http://forums.adobe.com/message/4904789#4904789
openURL( 'www.google.com' );
function openURL( address ) {
var f = File( Folder.temp + '/aiOpenURL.url' );
f.open( 'w' );
f.write( '[InternetShortcut]' + '\r' + 'URL=http://' + address + '\r' );
f.close();
f.execute();
};


Copy link to clipboard
Copied
Hi @Js1212 , Try this where the URL string is the complete address (include http: or https: as needed)
openURL('https://www.google.com/');
function openURL( address ) {
var f = File( Folder.temp + '/aiOpenURL.url' );
f.open( 'w' );
f.write( '[InternetShortcut]' + '\r' + 'URL=' + address + '\r' );
f.close();
f.execute();
};
Copy link to clipboard
Copied
Copy link to clipboard
Copied
Worked for me. Does it work if you run from the Scripts panel?

Copy link to clipboard
Copied
no,it is not working for me
i have been running it from the scripts panel in indesign.....hmmmmmm
Copy link to clipboard
Copied
The text file is written to your system temp file, so it could be a security problem. Does it work if you write it to the desktop?
openURL('https://www.google.com/');
function openURL( address ) {
var f = File( Folder.desktop + '/aiOpenURL.url' );
f.open( 'w' );
f.write( '[InternetShortcut]' + '\r' + 'URL=' + address + '\r' );
f.close();
f.execute();
};
The temp folder can also be:
var f = File( Folder.temp.fsName + '/aiOpenURL.url' );Copy link to clipboard
Copied
OK. Ill wait a little longer, but it looks like I cant do what I need simply in JS.
The difference in my request and the answers suggested is I already have the page open in the browser, and need to get at the variable data hidden in the page.
I will wait a little longer to see if any one else has an ideas, otherwise I will assume it cannot be done.
Thanks anyway.
Roy
Copy link to clipboard
Copied
This is what I suspected… Your problem lies with the URL of of the already open browser… Do your main code in JS and call out a do script to get this string…?

Copy link to clipboard
Copied
You must pass a valid URL. Did you try with a valid URL? www.google.com is not a valid URL, even though you can type it in a browser.
Copy link to clipboard
Copied
Hi @Test Screen Name , The original code was assuming all addresses start with http://. In case it wasn’t obvious, I changed the write line from:
f.write( '[InternetShortcut]' + '\r' + 'URL=http://' + address + '\r' );
To:
f.write( '[InternetShortcut]' + '\r' + 'URL=' + address + '\r' );
so that a complete URL is needed and will work.

Copy link to clipboard
Copied
You can use the hyperlinkDestination object to launch the browser using javascript. The idea is to add a hyperlinkdestination to a document and the use its showDestination method to open the browser. See the sample code below
var h = app.documents[0].hyperlinkURLDestinations.add("www.google.com")
h.showDestination()
The above code requires a document to be opened in InDesign
-Manan

Copy link to clipboard
Copied
I like this universal solution and the cost of creating both a dummy doc and hyperlink may not be critical.

Copy link to clipboard
Copied
What about using UXP Script?
You can communicate with BridgeTalk even from versions that cannot use UXP Script.
#target "indesign"
if (parseFloat(BridgeTalk.getSpecifier("indesign", -100).split("-")[1]) < 18) {
alert("InDesign with UXP is not installed.");
exit();
}
if(!BridgeTalk.isRunning(BridgeTalk.getSpecifier("indesign", -100))) {
BridgeTalk.launch(BridgeTalk.getSpecifier("indesign", -100), "background");
}
var myBridgeTalk = new BridgeTalk;
myBridgeTalk.target = BridgeTalk.getSpecifier("indesign", -100);
myBridgeTalk.body = """
if(app.documents.count() == 0){
app.documents.add(); // It doesn't seem to work without the document.
}
app.activeWindow.minimize();
app.insertLabel("response", "");
app.doScript(\"\"\"
await (async () => {
return new Promise((resolve, reject) => {
try{
const xhr = new XMLHttpRequest();
xhr.open("GET", "https://reqres.in/api/users/2", true);
xhr.onload = function(){
app.insertLabel("response", xhr.response);
resolve();
};
xhr.send();
} catch (e) {
resolve(e);
}
});
})();
\"\"\", ScriptLanguage.UXPSCRIPT);
for(var i = 0; i < 100; i++){
if(app.extractLabel("response") != ""){
var myExtractLabelValue = app.extractLabel("response");
break;
}else{
$.sleep(100);
}
}
app.insertLabel("response", ""); // Remains if not initialized
myExtractLabelValue; // Return value
""";
myBridgeTalk.onResult = function(result) {
alert(result.body);
}
myBridgeTalk.onError = function(error) {
alert("Error: " + error.body);
}
myBridgeTalk.send(10000); // If not supplied or 0, the message is sent asynchronously, and the function returns immediately without waiting for a result.
I used this as a reference for XMLHttpRequest.
I don't know how to use fetch.
Please someone tell me.
https://developer.adobe.com/indesign/uxp/uxp/reference-js/Global%20Members/Data%20Transfers/fetch/
-
- 1
- 2

Get ready! An upgraded Adobe Community experience is coming in January.
Learn more
 AdChoices
AdChoices
{kind=link}
{kind=link}