
RoboHelp 2017 - In PDF generation, how can I avoid getting XE fields polluting my Bookmarks
Background
Hello RoboHelpers! It's been a while.
- RH 2017 latest update.
- Word from Office 365
- Adobe Acrobat DC 2015
For my work, I have about 40 Microsoft Word *.doc files of varying sizes with thousands of hidden XE fields (Index fields) in them. The Word docs are created from RoboHelp 2017 sections. I need to convert these .doc files into PDF files every six months or so when we publish a new version of our software. I use Adobe Acrobat DC to do the conversion into PDF.
I can convert these Word docs one at a time, and they look just how I want them, as long as I open them up inside Word, one by one, and from the Acrobat add-in menu in Word, I choose Create PDF.
However...
The Problem
In Acrobat DC, if I try to be efficient and convert all the .doc files in a group by using File > Create > Create Multiple PDF Files, then hidden XE index fields on the headings end up polluting my Bookmarks in the Bookmarks pane of my PDF files.
Here's just one example:
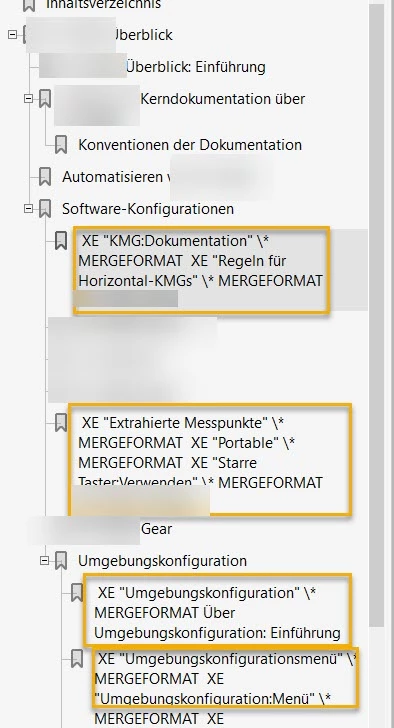
The strange thing is that this seems to occur only with the Bookmarks. The actual topic text in the PDF files is free of the XE entries.
The Question(s)
Does anyone else see this?
How can I prevent my Bookmarks from getting polluted by these XE entries when I generate multiple files like this?
What I've Tried
I've looked at the various settings in Acrobat and didn't see anything that controls this.
I've looked online and found this related post, but couldn't find a solution:
Thanks in advance.
