

Question
Indexing by own list
Hi.
In the first step I try to load a text-based list to create an index with certain topics. The loading is not the problem:
var myDoc = app.activeDocument;
app.doScript(main, ScriptLanguage.JAVASCRIPT, undefined, UndoModes.ENTIRE_SCRIPT, "Funktionsprozess");
function main() {
var myList = File.openDialog ("Indexliste laden");
if (!myList) exit();
myList.open ('r', undefined, undefined);
var theText = myList.read();//+'\n';
theText = theText.replace(/ +\n/g, '\n').replace(/\n+/g, '\n');
var words = theText //.replace(/\s+/g, '\n');
var words = theText.split("\n");
listLength = words.length;
myList.close();
function makeMyList() {
app.documents.everyItem().indexes.everyItem().topics.everyItem().remove()
newIndex = myDoc.indexes.add()
for (var i = 0; i<listLength; i++){
myWord = words[i];
if (myWord != "") {
newTopic = myDoc.indexes[0].topics.add (myWord);
myDoc.indexes[0].topics.add(myWord);
myDoc.indexes[0].update();
}
}
}
makeMyList();
}
I had to change the script because making a mistake (wanted to use a string instead an array for the enties)🙂Now it works but I also need the page numbers. This is how it looks like: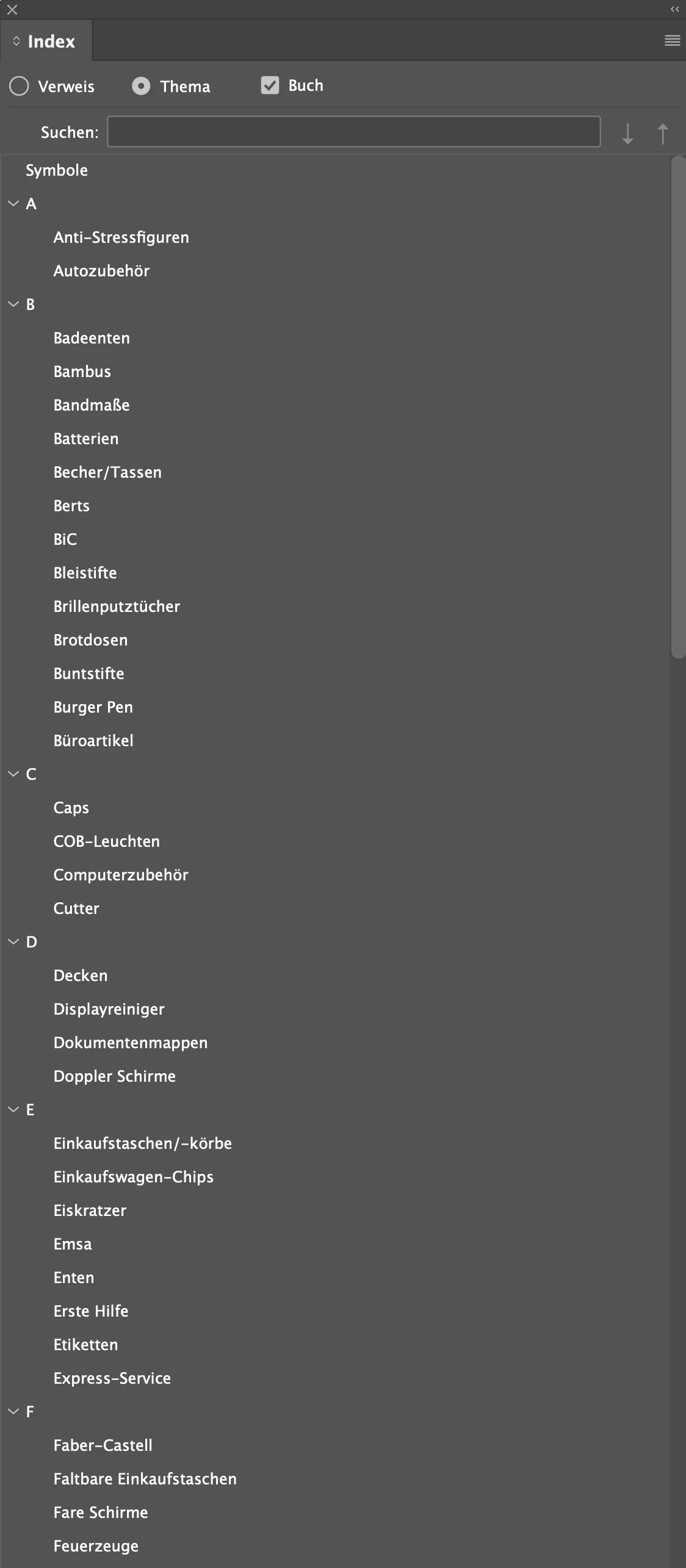
But I´m afraid, the imported topics needs to be at the references (Verweise) instead of the theme (Thema) to get the page numbers, isn´t it?