

- Home
- InDesign
- Discussions
- Re: Two aligned columns without using a table
- Re: Two aligned columns without using a table

Copy link to clipboard
Copied
I'm working on this section of text and for several reasons it needs to be set without separating the entry on the left and the definition on the right (as in what table cells would do).
Breaking it up into two column text is no good because the words need to be next to their definitions.
A simple tab seems like the correct answer until there's a two-line entry on the left column. When that happens the definition on the right is no longer aligned to the top of the left entry.
Does anyone have any ideas about how to make this work?
This is currently set in a table with two columns, but it needs to be taken out of this format. We are trying to use the index feature to compile a list of these words and definitions, but using a table makes it impossible to select the entry and definition together.



 1 Correct answer
1 Correct answer
Hi Uwe,
In fact, it's truly simple to be played [as often with me]! … 
You need 3 para styles:
• Green [you're right on its settings: it includes a "span" feature!]
• Blue / Red for the 2 "problematic" parts [as Vinny previously indicated => keep all para lines together]
… 1 supplementary one: the magical "Separator" para style! [no size, no leading, no color + "span" feature] -- totally invisible!
… and 2 regex [not 3! played in 1 click]:
Regex 1:
Find: \r
Replace by: $0@\$0
Find Format: "Red" pa
... 26
Replies
26
26
Replies
26

Copy link to clipboard
Copied
Make a hanging indent by setting the left indent to the same amount as your tab setting. Then, set the first-line indent to a negative of that value. For example, if your tab is set to 2", make your left indent 2" and your first-line indent -2".
Copy link to clipboard
Copied
Right, that would work for the "pasarlo…" entry in the screenshot, also achievable by placing an indent to here marker at the beginning of the definition.
The part I haven't figured out is for examples like the last entry, where the left column entry is two lines long.
Copy link to clipboard
Copied
I'm not sure there is a simple solution to that. The first lines of the two "columns" need to align, so you cant just tab after the bold on the left without having to sandwich the Roman on the right between two bits of the bold, and that would kill your index. There may be a way to jimmy this into something that works, but I don't have the time right now to look into it. Maybe later I'll get a minute, or maybe someone else will know a solution before that. Good luck.

Copy link to clipboard
Copied
Could this do the trick?
- Regular text
- Type > Insert Special Character > Other > Indent to Here
- Inserted a tab before the "Indent to Here" character. Then controlled the position of that tab using the Tabs panel or the Tabs section within a Paragraph Style

Copy link to clipboard
Copied
This would work for when there are multiple lines in the definition column, but not when there are multiple lines in the entry (left) column. That's the part I'm struggling with.
Copy link to clipboard
Copied
What about two adjacent text frames that are threaded together?
You could insert a Frame Break within the text which would force the text beyond that point into the next frame. The text is still one continuous piece which might allow for the kind of selecting you need to do.

Copy link to clipboard
Copied
So, NGWSP, why are tables off the table? That's really your best bet, IMHO.
~Barb

Copy link to clipboard
Copied
BarbBinder wrote
So, NGWSP , why are tables off the table? That's really your best bet, IMHO.
Hi Barb,
our OP states:
… using a table makes it impossible to select the entry and definition together.
True. There are two cells. One for the key entry and one for the value entry.
What I do not get is why both entries should be selectable in one go…
Regards,
Uwe
Copy link to clipboard
Copied
Thanks, Uwe. I missed that. But on reading it again, is the selection requirement to quickly add index markers?
We are trying to use the index feature to compile a list of these words and definitions, but using a table makes it impossible to select the entry and definition together.
One could set up all of the table formatting with nested styles (table styles, cell styles and paragraph styles), convert the table to text, index away and then convert back to a table. The nested styles would mean minimal reformatting after the reconversion.
~Barb
Copy link to clipboard
Copied
Hi,
It doesn't seem to be too hard to play … without a table construction! …



You just need to imagine a "span-separator" after each "red" para and some Grep find/replace enough relevant to achieve it [3, simplistic]
I've created an "index entry" covering 2 paras [blue + red]! It could be simple too to build an index from such a trick.
Best,
Michel, for FRIdNGE

Copy link to clipboard
Copied
Yes, I concur with Michel.
That's how I would do it too, but my main concern would be how bad would indesign be slowed down...
From my experience, splitting/spanning feature can really slow down the whole thing... 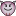
ps: don't forget to set up keep options in order to keep all paragraph lines together
ps2: would be interesting to see how the final index should look like
Copy link to clipboard
Copied
Hi Vinny,
Except that, for layout eases, I will use a table structure! 
... and this choice of the table presents no difficulty using an adhoc [simple] script to play an index built on double cell! …
Best,
Michel
Copy link to clipboard
Copied
vinny38 wrote
…
ps2: would be interesting to see how the final index should look like
Yes!
BESIDES. What else could speak against a solution with empty paragraphs, other than the effort to convert tables to texts?
Export to EPUB? Accessibility issues when creating PDFs for screen readers?
With the solution created by Michel didn't we add things on the contents level?
1. An end of paragraph marker between tabular data.
2. An empty paragraph after each row of tabular data.
Regards,
Uwe
Copy link to clipboard
Copied
I just did a section using Michel's solution. Created a small sample index and produced the index. Then I had to do a bit of a creative GREP search, but that did give me the desired results.
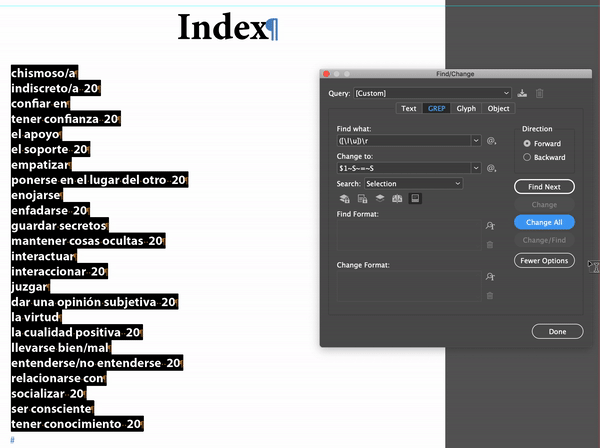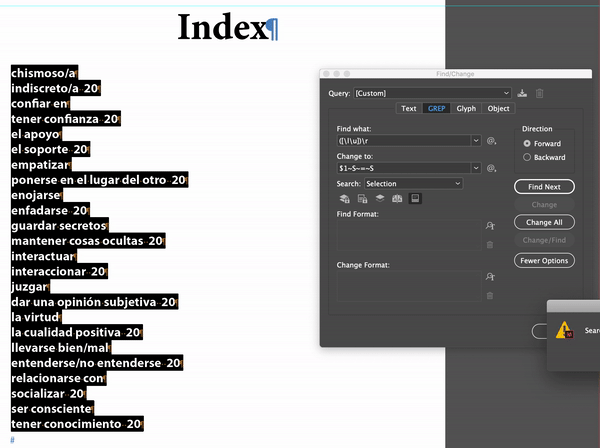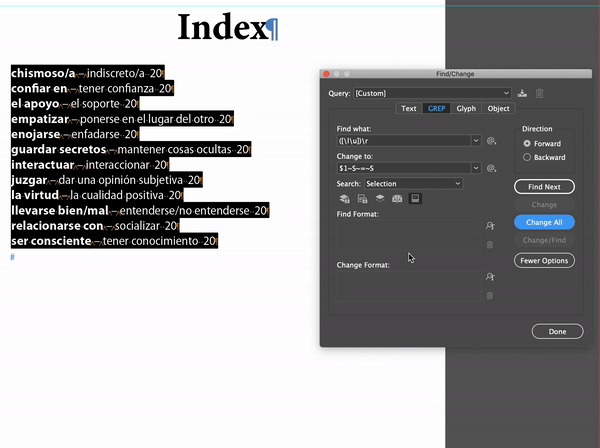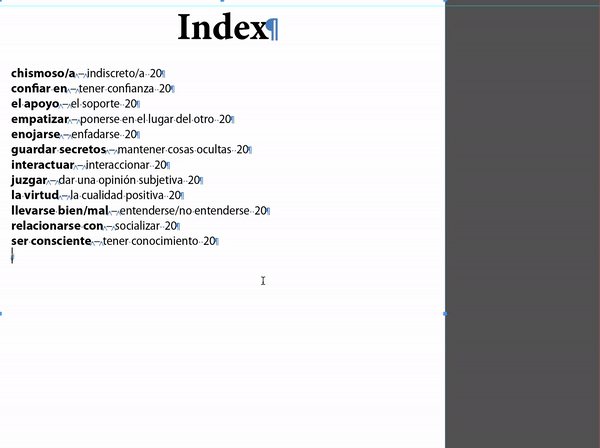
Copy link to clipboard
Copied
Cool! … We have an happy winner [you!] in the game! 
Best,
Michel

Copy link to clipboard
Copied
Michel, I am working with OP on this project and I think this is a brilliant solution. Thank you for your time!
Copy link to clipboard
Copied
Hi Michel,
I'm trying to follow you with your idea and still cannot make it work.
The green paragraphs get a span option to span all columns, that's clear and is working for me.
But how did you wrap the red paragraph to the next column?
Are you working with the Keep Options and did you set Start Paragraph to Next Column ?
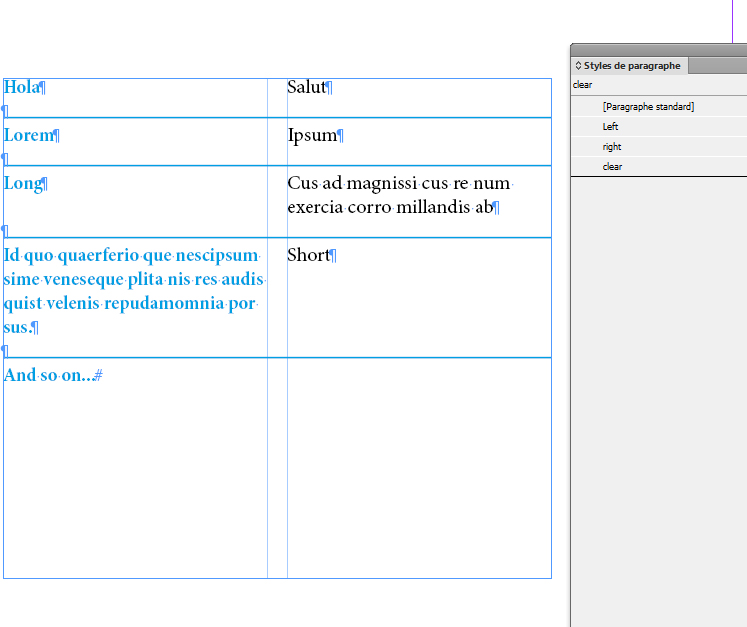
As you can see below my key paragraphs ( they should go to the left column ) and the value paragraphs ( they always should go to the right column ) are alternating with each other. I did three paragraph styles because I suspected that I need at least two for my key paragraphs. Maybe not, maybe more. Right now the two are all the same in definition but the fill color. I also did one paragraph style for the value paragraphs.
Currently the Keep Options of paragraph style ValueItems is shown below with
Start Paragraph set to Anywhere
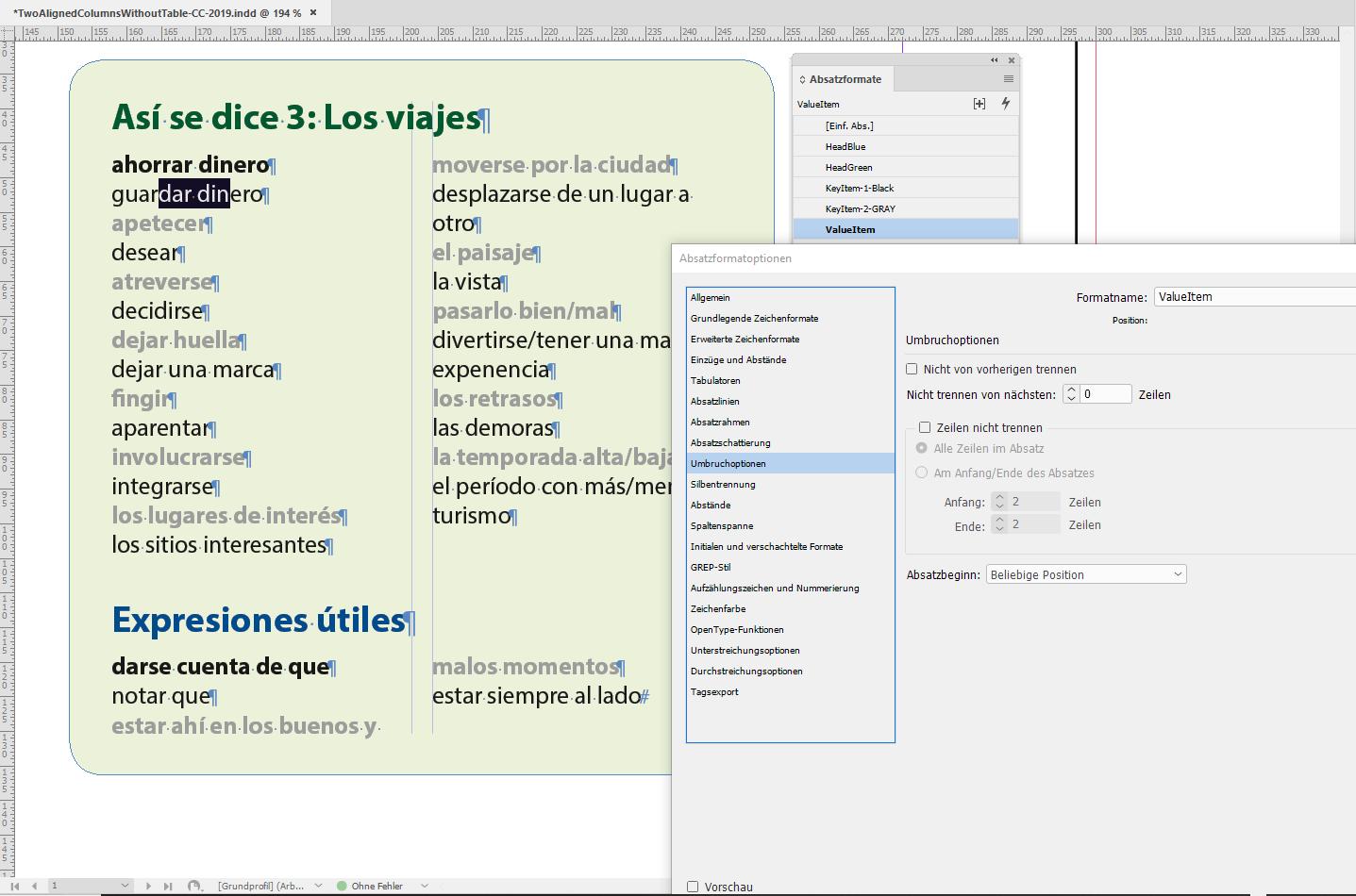
If I change this to Start Paragraph set to Next Column the first value paragraph will indeed go to the second column. Exactly what I want. But from then on the things do not go right. The second entry for the next key paragraph starts in the second column. That's not the thing I wanted to do. And the rest of the text goes to overset.
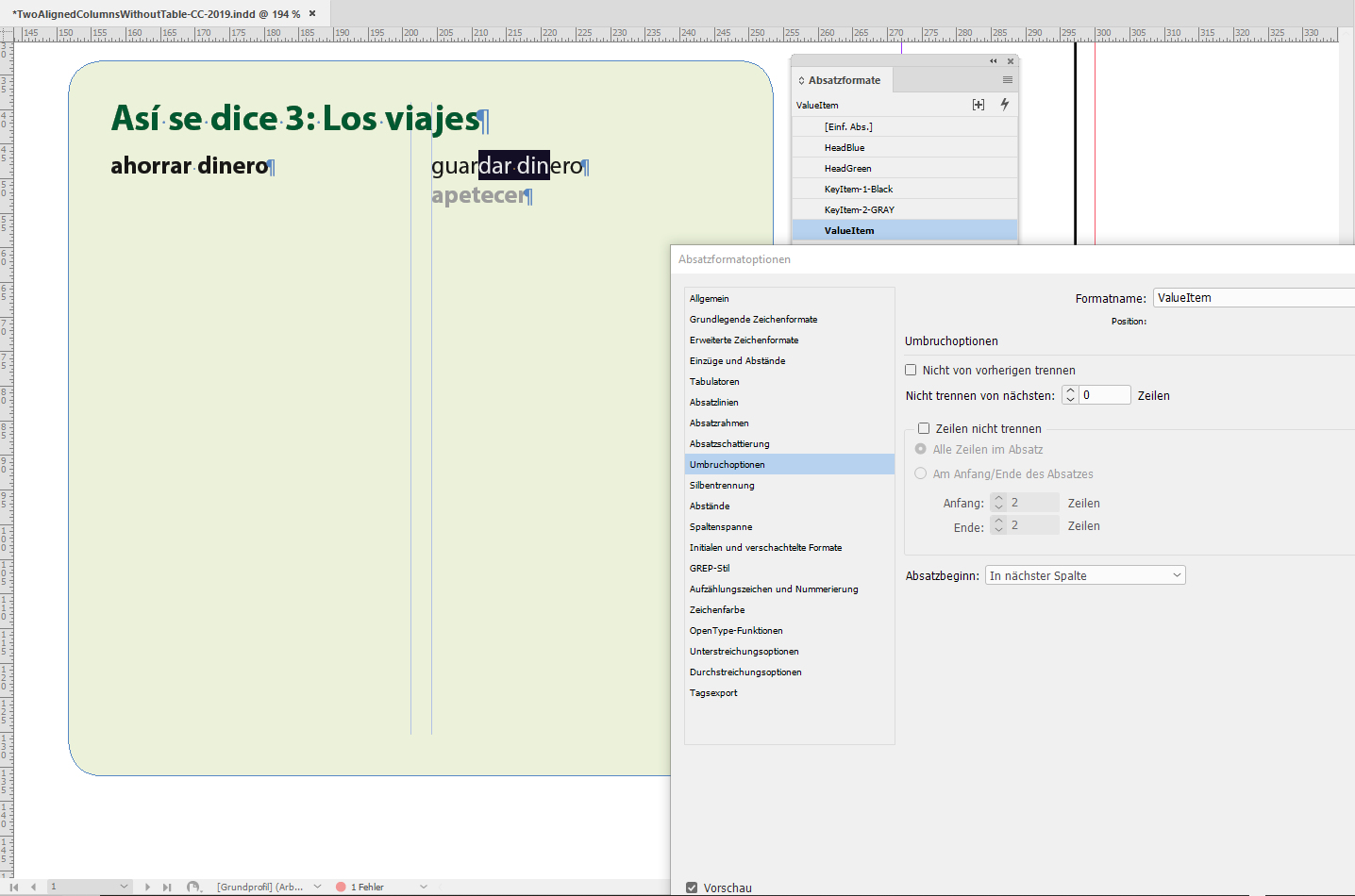
Here the Keep Options of my KeyItem-2-GRAY paragraph style with
Start Paragraph set to Anywhere
Obviously you are doing something very differently just from the start.
Can you show some details of the formatting of your blue and red paragraphs?
Regards,
Uwe
Copy link to clipboard
Copied
Hi Uwe,
In fact, it's truly simple to be played [as often with me]! …
You need 3 para styles:
• Green [you're right on its settings: it includes a "span" feature!]
• Blue / Red for the 2 "problematic" parts [as Vinny previously indicated => keep all para lines together]
… 1 supplementary one: the magical "Separator" para style! [no size, no leading, no color + "span" feature] -- totally invisible!
… and 2 regex [not 3! played in 1 click]:
Regex 1:
Find: \r
Replace by: $0@\$0
Find Format: "Red" para style
Regex 2:
Find: @(?=\r)
Replace by: nothing
Replace by Format: "Separator" para style
That's all!
Best,
Michel
Copy link to clipboard
Copied
Uwe,
you are missing the "span-separator".
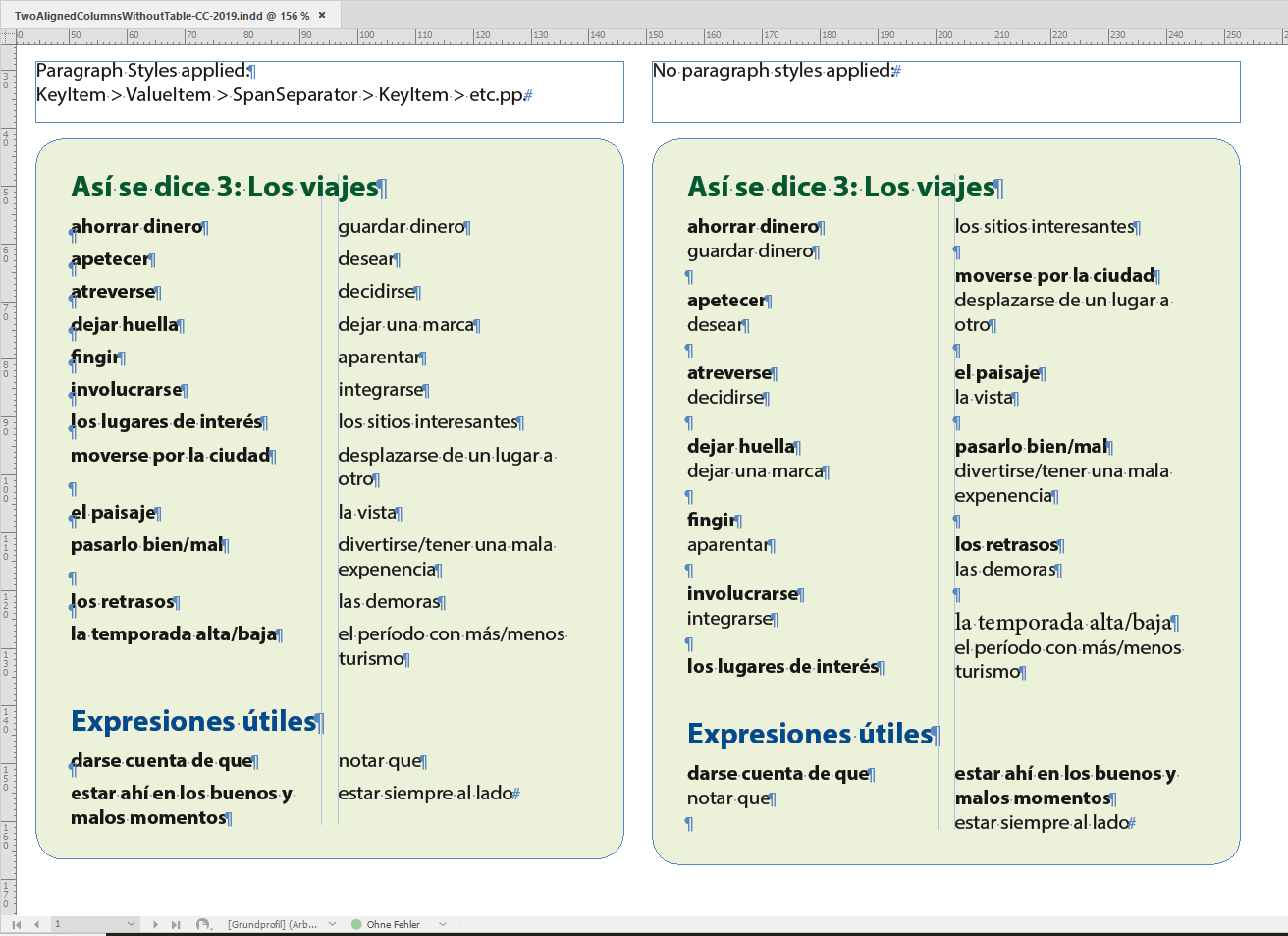
If you use a 2 columns text frame, apart from the headers, you need 3 styles:
"left": no spanning + keep all lines together + start anywhere + next style: "right"
"right": no spanning + keep all lines together + start anywhere + next style: "span-separator"
"span-separator": span over all columns + start anywhere + next style: "left"
For better understanding, I set a paragraph rule for span-separator, but at the end, you can make it "invisible":
However, I agree with Michel than a script that would index contiguous cells would probably be the best option here.
Copy link to clipboard
Copied
About this last point:
The script finds the contents (without the carriage-return) of the "Blue" paras ==> Array 1
The script finds the contents (without the carriage-return) of the "Red" paras ==> Array 2
… and creates, e.g. at the beginning of each "Blue" para, an index entry, concanating:
index entry 0 => Array 1[0] + … + Array 2[0]
index entry 1 => Array 1[1] + … + Array 2[1]
...
The "…" is what the user wants (a tab for example).
We could have something like that too:
Xxxxx xxx xxxxx [yyy yyy yyyyy]……………… 1
including Grep styles in the "Index Entry" para style!
Best,
Michel
Copy link to clipboard
Copied
This seems like a good option as well. I'll look into how I can build this out. Thank you!
Copy link to clipboard
Copied
Here, to do all: 1 click! … so 1 second!
I've always thought that a "click" is the easiest way to do things!
Best,
Michel
Copy link to clipboard
Copied
Hi Vinny, hi Michel,
thank you very much for clarification!
Makes perfectly sense to use an empty paragraph with span all columns between two key/value-pairs.
Regards,
Uwe
Copy link to clipboard
Copied
Ah, this makes the answer make sense. Thanks Michel and Vinny38! It does seem like a complex option, but it makes sense.
I agree that a script would be the easiest option, I just don't know much about writing scripts!
In some ways, Barb's idea might be the simplest and easiest to implement though. We just have to generate the index once. We can just duplicate the pages containing these tables, convert the tables to text, build the index, then delete the duplicates, keeping the original table-formatted versions in the document and keep the index.
Thanks all so much for your answers and help thinking through this problem!
-
- 1
- 2

Find more inspiration, events, and resources on the new Adobe Community
Explore Now
 AdChoices
AdChoices